AkumaはWebブラウザ上で利用可能な画像生成AIサービスです。
画像生成モデルはStable Diffusionをベースとしており生成される画像のクオリティは勿論高いのですが、Akumaでは他にもリアルタイム画像生成やAI学習などのユニークな機能があります。
基本的には有料サブスクリプション登録が必要ですが無料でも何回か試すことは出来るため、画像生成に興味があるならばまずはアクセスしてみると良いでしょう。
運営組織について
AkumaはKinkaku株式会社という名称の日本企業が運営・提供しているサービスであり、この記事で紹介するAkuma.aiがメインプロダクトのようです。Akumaって名前はなかなか攻めてますね。
2020年に設立された企業とのことですが、これからも邁進いただきたいですね(日本贔屓)
アカウント登録方法
Akumaの利用にはGoogleアカウントの登録が必須です。Webサイトへのアクセス方法から順に説明していきましょう。
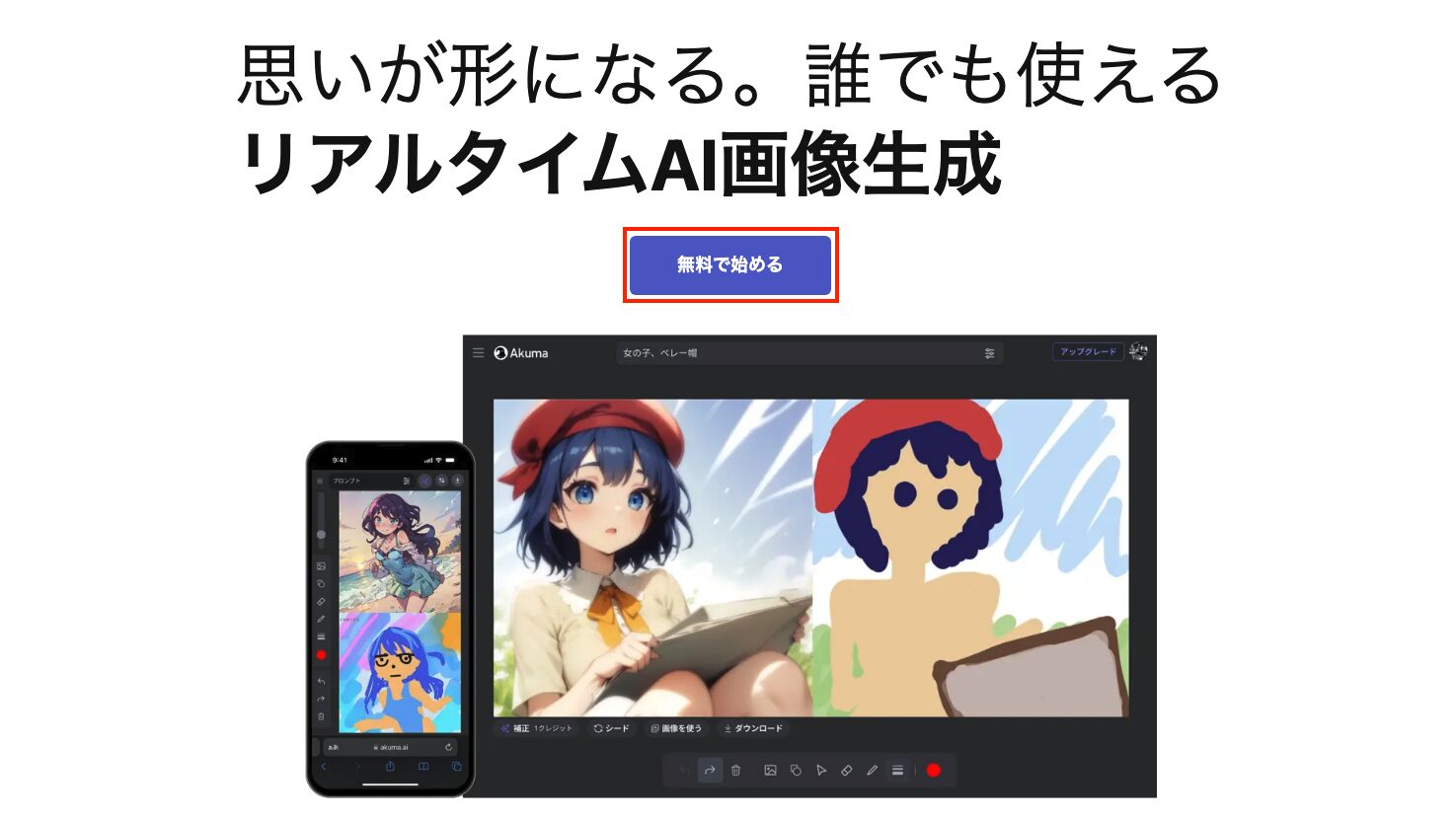
- STEP1/4任意のWebブラウザからAkumaにアクセスする
https://akuma.ai/jaにアクセスし「無料で始める」をクリックします。

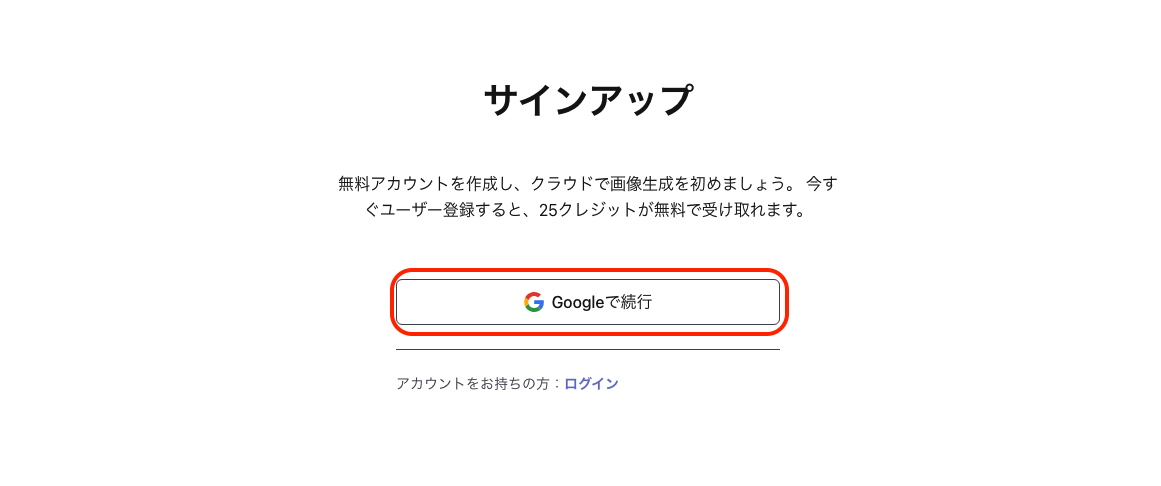
- STEP2/4ログイン方式を選択する
任意(1種類)のログイン方式を選択します。

Akumaは潔い
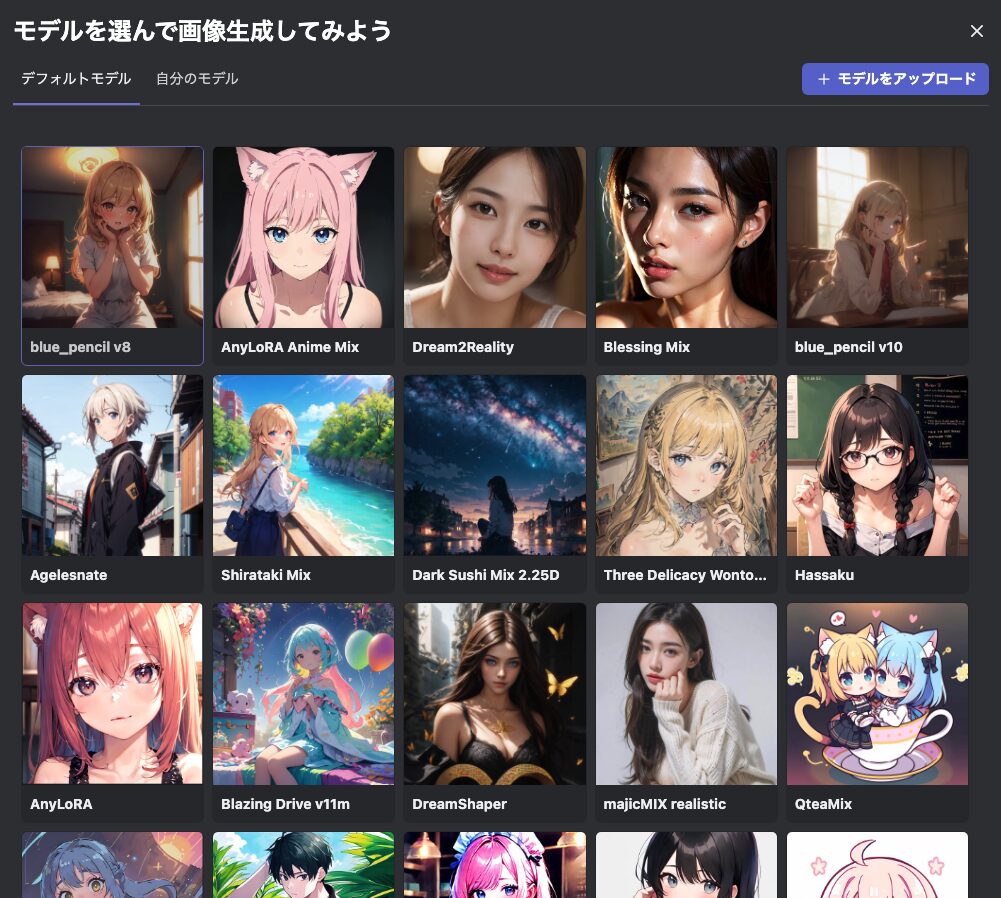
- STEP3/4モデルを選択する(任意)
アカウント登録後に画面が画像生成ページへ遷移し、そのまま画像生成を促されます。
生成を行うのであれば画面に従ってモデルを選択しますが、そうで無ければ右上の「☓」をクリックして閉じても構いません。

- FINISHログインできていることを確認する
下図のような画面に遷移できていればログインは正常に完了しています。

なお、初回ログインであれば25クレジットがプレゼントされています。
利用料金について
2024年9月時点では初回ログイン時に使い切りの25クレジットがもらえますが、無料プランだとクレジットのリセットや補充が無いので継続的に利用するのであればアップグレード(サブスクリプション登録)が必要です。
画面右下の「アップグレード」をクリックすると以下のようなラインナップが表示され、そのまま登録できます。

Akumaの使い方
テキストから画像を生成する
画面左側のメニューから「生成」をクリックして画像生成ページに移動し、画面下部のテキストボックスに生成したい内容(プロンプト)を入力することで画像が生成されます。

より具体的な生成手順は以下の通りです。
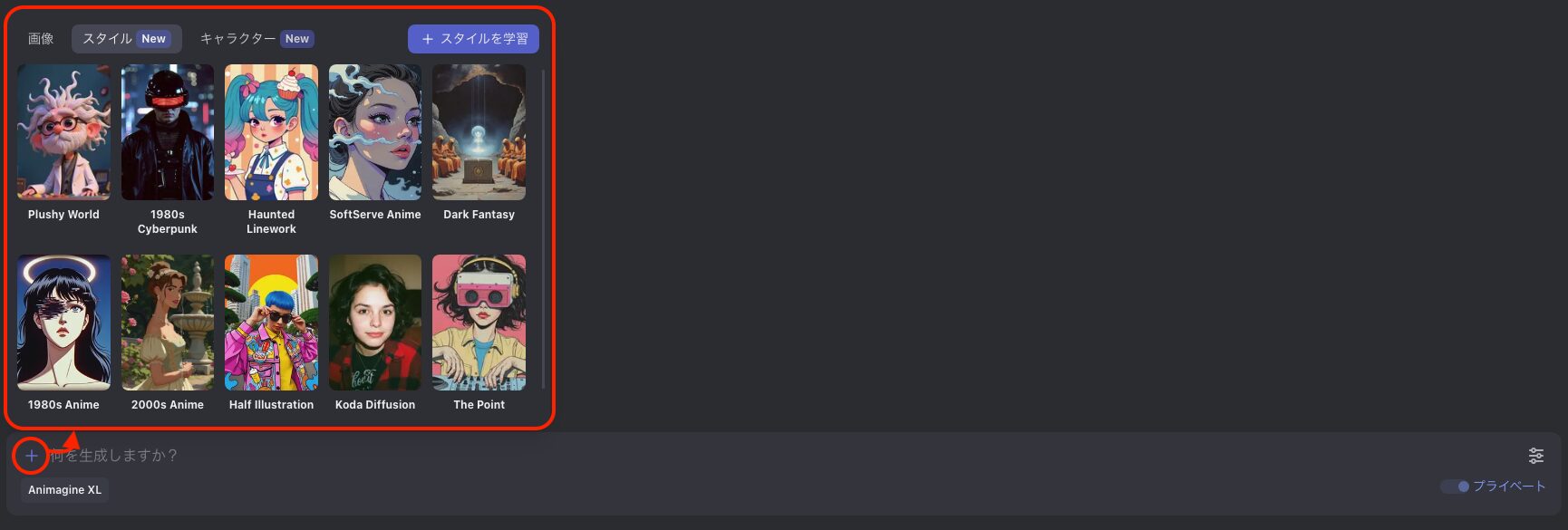
- STEP1/4参照情報の設定を行う(任意)
テキストボックス左側の「+」アイコンをクリックすると参照する画像・スタイル・キャラクターの設定が可能です。

簡潔に説明すると画像は構図を、スタイルは画風やコンセプトを、そしてキャラクターは対象となるキャラクター画像そのものを参照情報として取り入れます。
また、上記のうちスタイルとキャラクターについては自分で学習させてオリジナルのものを作ることも出来ます。
Midjourneyで言うところのStyle RefやCharacter Refに近い機能ですね。
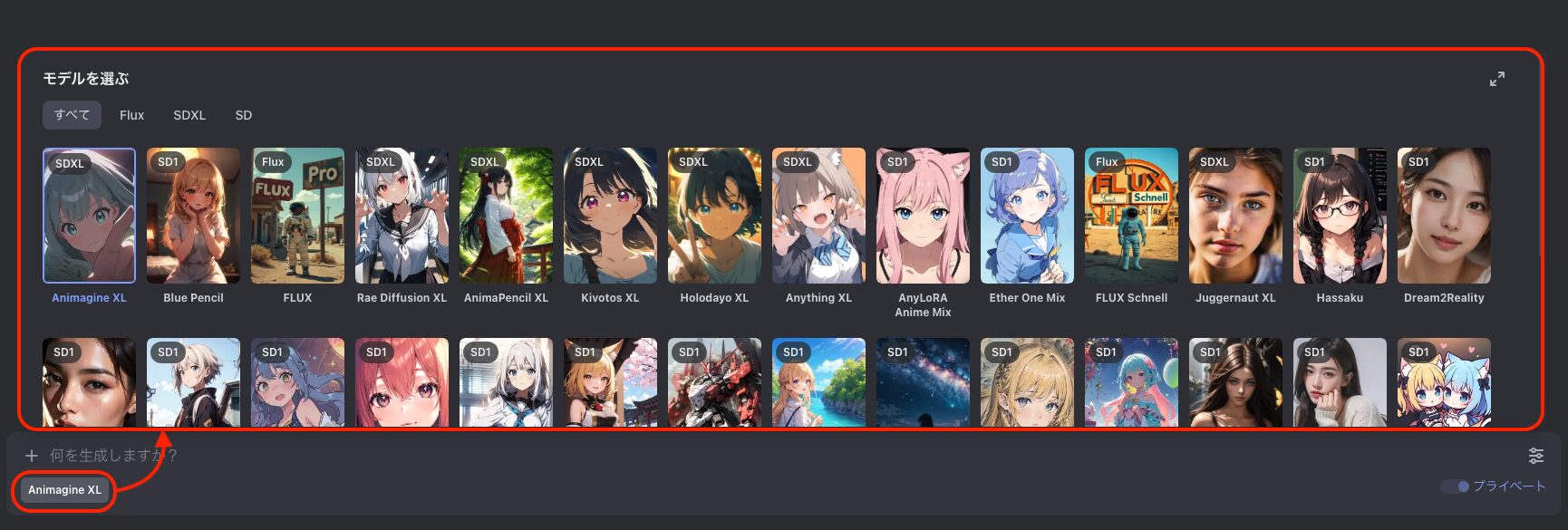
- STEP2/4モデルを選択する(必須)
テキストボックスの下部をクリックするとモデルを選択することが出来ます。
モデルは生成される画像に大きく影響を及ぼす要素であり、同じプロンプトでもモデルが異なると画風から何から全く異なることも往々にしてあります。
実際のところ使ってみないことにはモデルの良し悪しもわかりませんが、Akuma側で用意しているモデルであればハズレを引くことも無いでしょう。
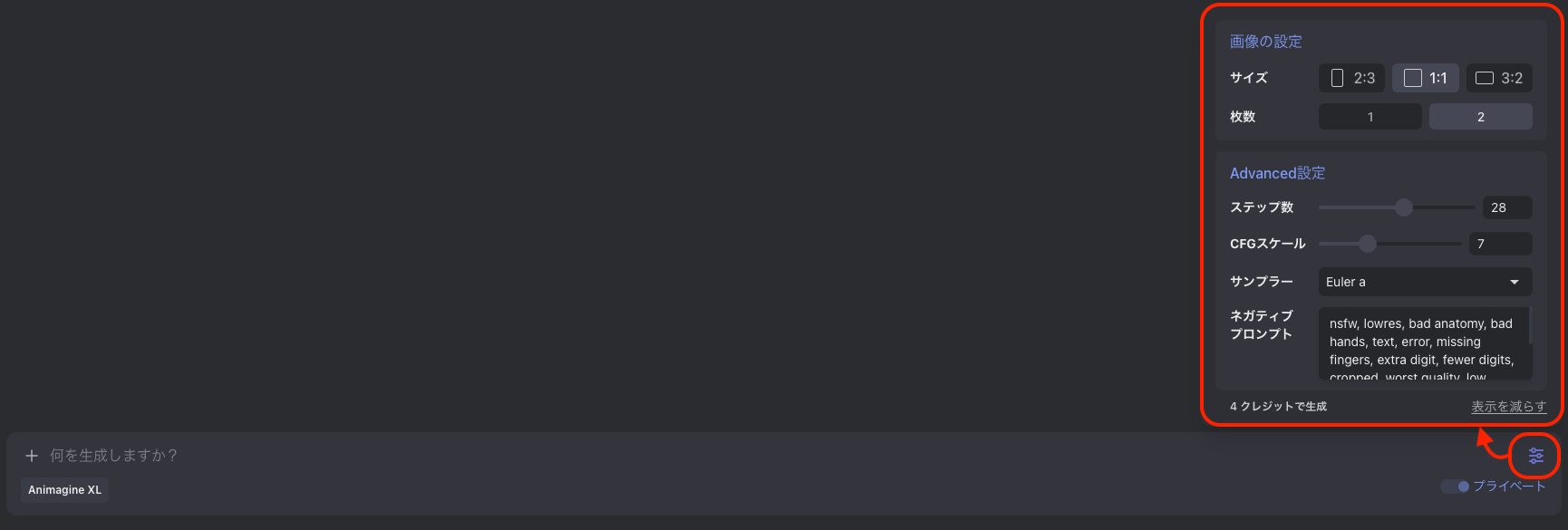
- STEP3/4生成される画像の設定を行う(推奨)
テキストボックスの右側にあるメニューをクリックすると画像の設定を行うことが出来ます。
地味に消費クレジットが明記されているので確認漏れが無いように
設定可能な項目はモデルによって異なりますが、おおよそ項目として挙がってくるのは以下の通り。
項目 説明 サイズ 生成される画像のサイズというかアスペクト比率。
よくみる比率である16:9はおそらくありません。枚数 一度の処理で生成される枚数。
生成数が多いと一度に消費するクレジットも増える。ステップ数 1枚の画像生成にかける処理数。
数値が高いほど描写が細かくなる。CFGスケール プロンプトの反映度合い。
数値が高いほどプロンプトの内容を正確に描写するが、高すぎると逆に画像が安定しなくなる。サンプラー 画像生成方式の指定。
モデルによっては利用できないものがあったり個人の好みがあったりするので単純にこれを使えば良い…というものではないが、DPM++ 2M Karrasが比較的シェアが高め。ネガティブプロンプト 画像に含めたくない要素の指定。
基本的にはデフォルトのままで良い。 - FINISHプロンプトを入力する
生成したい画像を説明するプロンプトを入力しEnterキーを押すと画像が生成されます。

プロンプトは日本語と英語に対応しています。また、文章よりは単語を羅列したほうが結果に反映されやすいようでした。

生成された画像をクリックすると編集画面に遷移し、ダウンロードや拡大(アップスケール)などを行うことが出来ます。
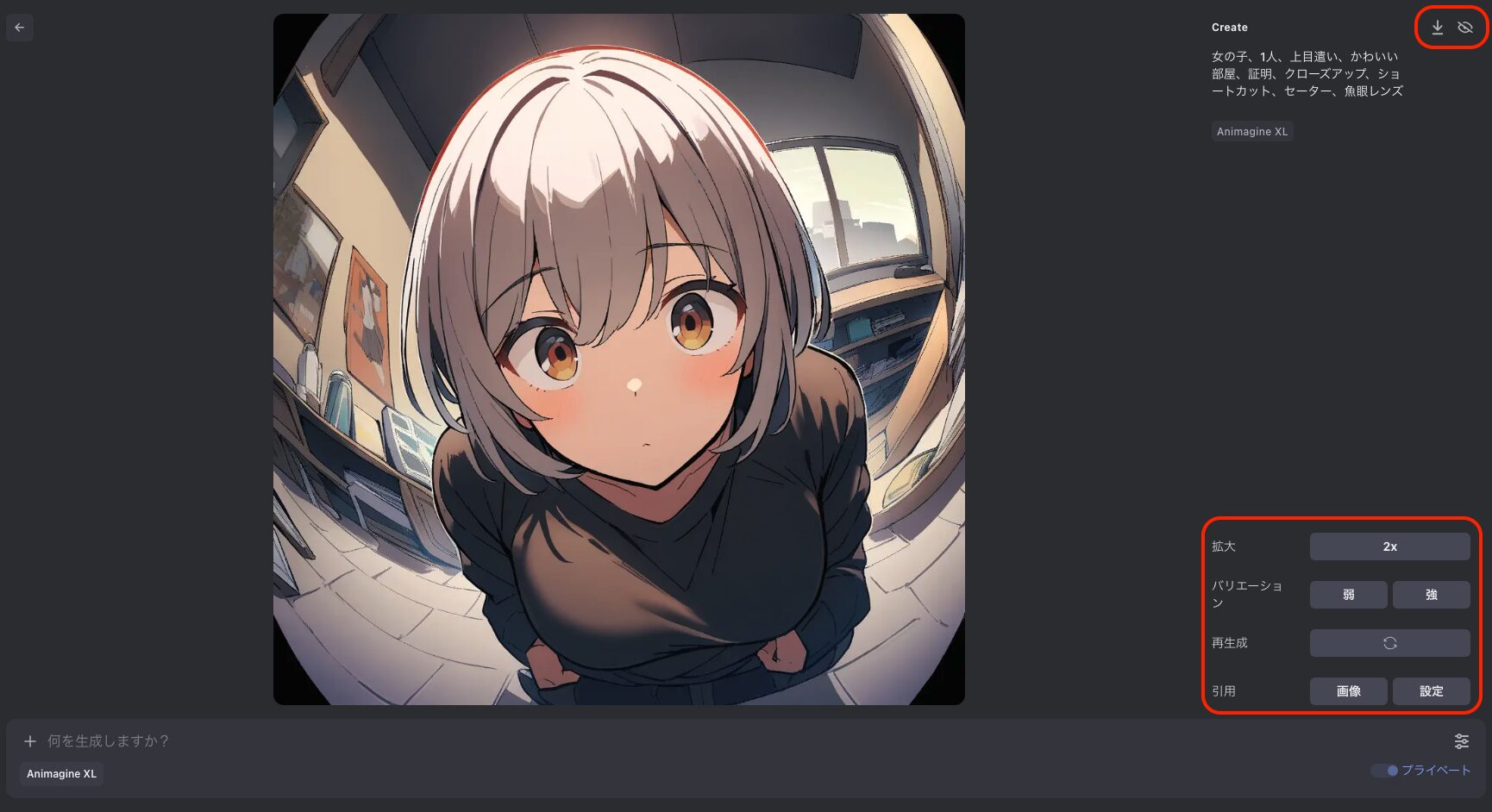
編集画面右下のメニューから選択可能な項目の詳細は以下の通りです。なお、「引用」以外は都度クレジットを消費します。
| 項目 | 説明 |
|---|---|
| 拡大 | 画像のサイズを2倍に拡大する。 拡大時に微妙に絵柄が変わることもある。 |
| バリエーション | 元の画像に対して微妙な変化を付ける。 |
| 再生成 | 同じプロンプトで新たに画像を生成する。 |
| 引用 | 参照情報として画像やプロンプトをセットする。 |
AIキャンバスを利用する
画面左側のメニューから「AIキャンバス」をクリックすると、フリーハンドで描いた絵をAIがリアルタイムで補正してくれるAIキャンバス機能を使うことが出来ます。
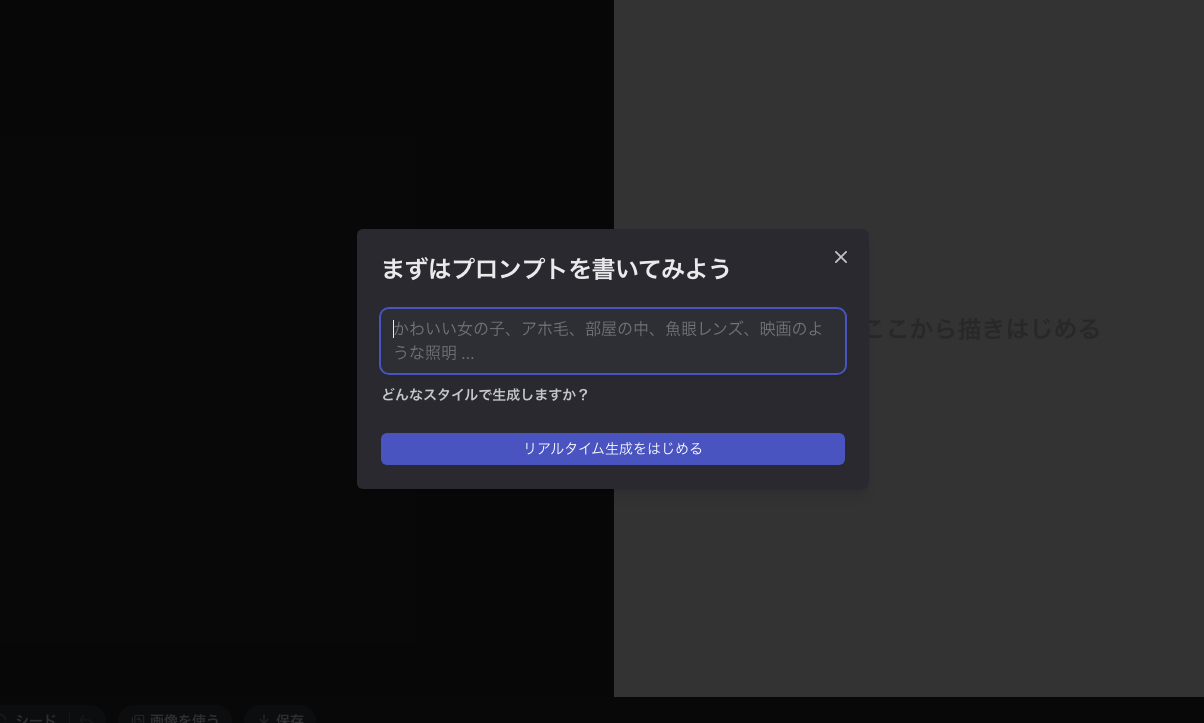
「AIキャンバス」にアクセスすると「まずはプロンプトを書いてみよう」と促されるので、書きたいものをイメージしてプロンプトを入力したあとに「リアルタイム生成をはじめる」をクリックします。
そうするとキャンバス画面が開くのであとはもう自由に書いていきます。
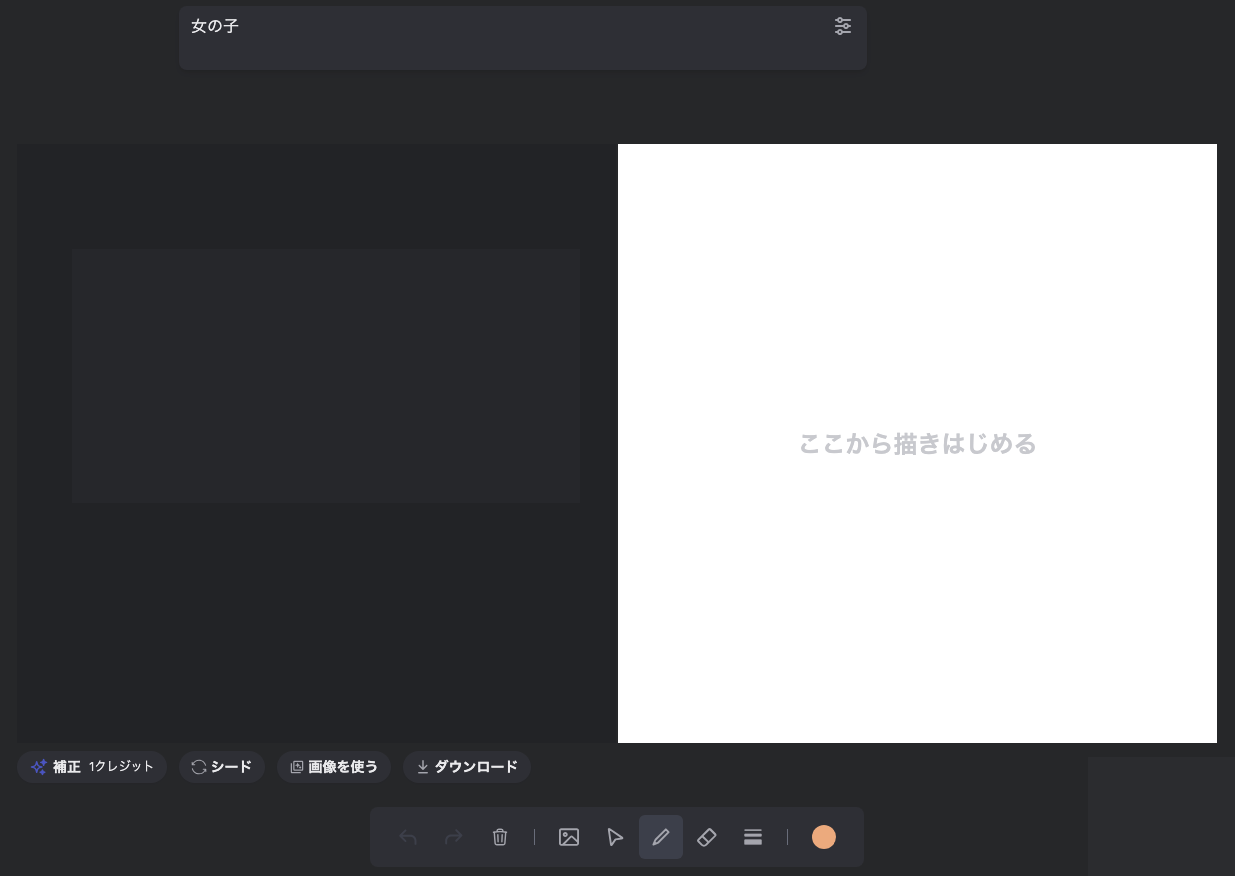
AIキャンバスで利用可能な項目をざっくりまとめます。
| 項目 | 説明 |
|---|---|
| スタイル | AIによる補正の傾向。 |
| AIの強さ | AIによる補正の強さ。 |
| LoRA | 画像を構成する要素。 手持ちのLoRAファイルをアップロードすることで利用可能。 |
| 仕上げ | 画像を高画質化する。1クレジットを消費。 |
| シード | 画像の傾向。シード値が変わると画像の構図やら何やらも変わる。 |
| 画像を使う | AIが補正した画像をキャンバスにコピーする。 |
また、ちょっとバージョンが古いですが実際に生成してみた様子は以下。ご覧のようにどれだけ稚拙な絵を書いたとしてもAIがいい感じに補正してくれます。

スタイルやキャラクターを学習させる
画面左側の「学習」メニューから「+ AIに学習させる」を選択すると、手持ちの画像を使ってスタイルやキャラクターを学習させることが出来ます。

「+ AIに学習させる」を選択すると以下のような設定画面が表示されるため、必要な内容を入力して「学習を開始する」をクリックします。
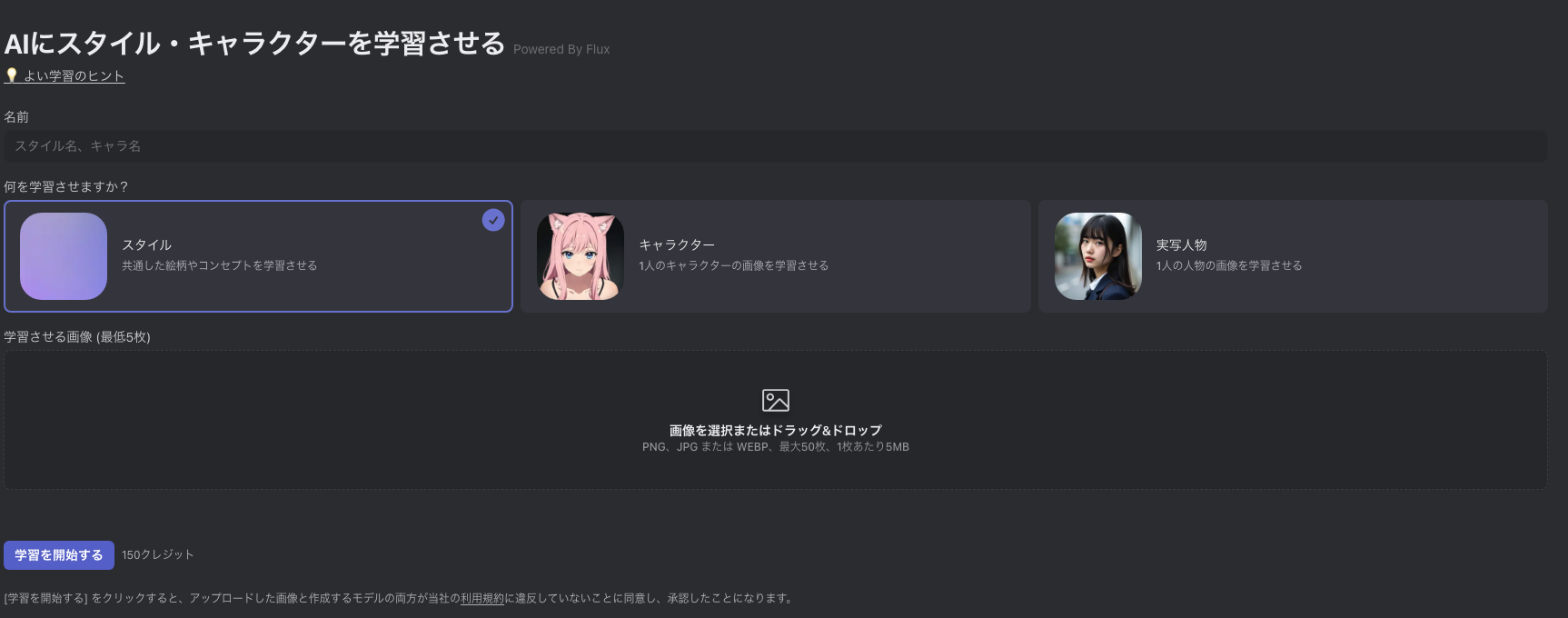
学習には数十分掛かります。気長に待ちましょう
というわけで試しに以下のような内容で学習をさせてみることにします。ちなみに元となる画像はMidjourneyのCharacter Refを利用して集めました。本末転倒?
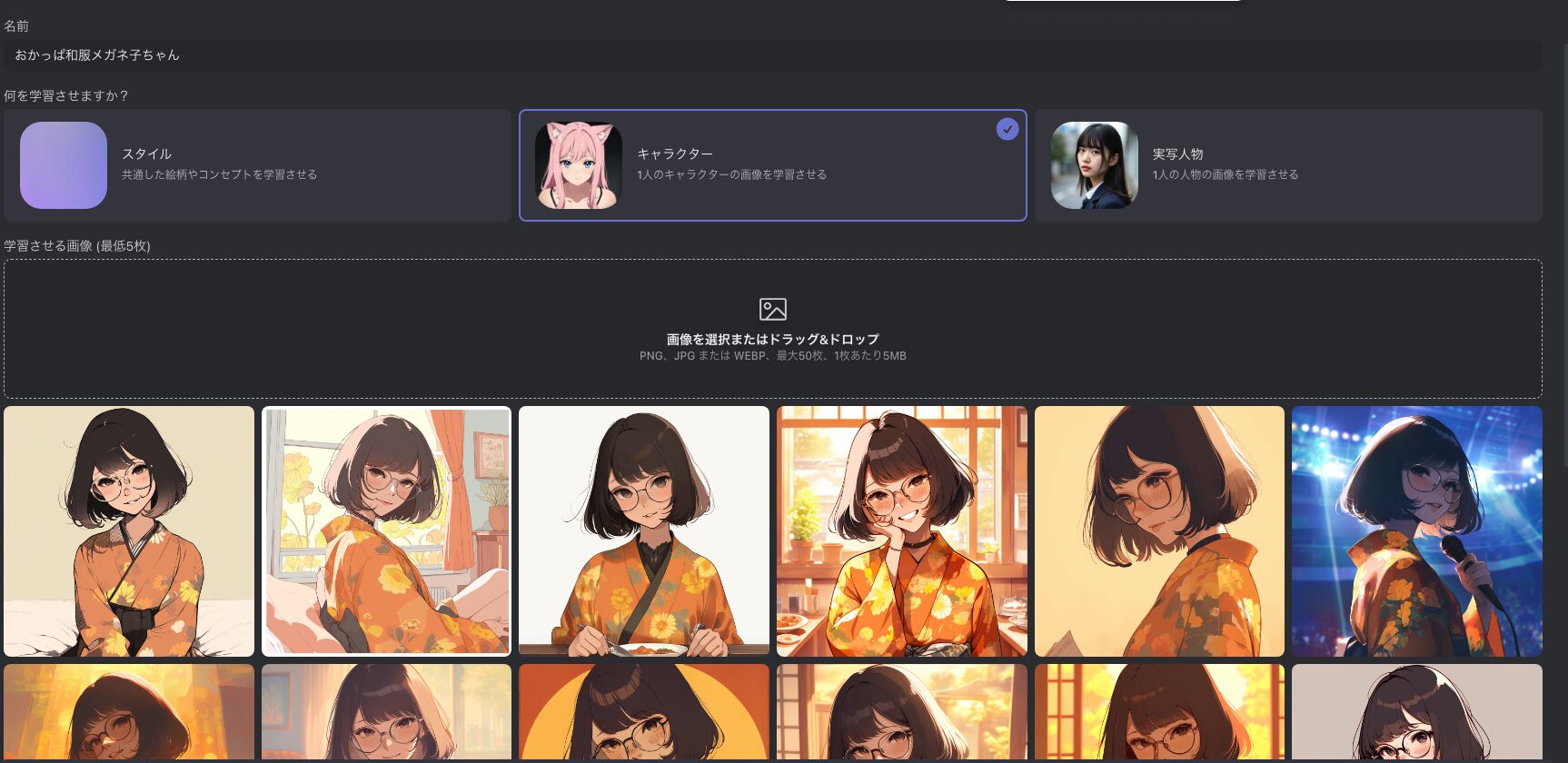
学習が完了したらあとは画像生成時に学習したセットを選択し、通常通りにプロンプトを入力すると学習結果が反映された画像が生成されます。

モデルはFLUX固定
使用した感想
数少ない日本語をメインで扱える画像生成サービスであり、生成される画像の質も十分に高いことから扱いやすいサービスです。
「AIキャンバス」はLeonardo.AIにも近しい機能はありますがAkumaの方が細かい調整が効き、「学習」に関しては2024年9月時点ではまともに扱っているのがMidjourneyぐらいしか無いものもあり、当初想定していた以上に画期的なサービスとなっています。