
TensorArt(テンソルアート)はWebブラウザ上で利用可能な画像生成サービスです。
画像生成AIの代名詞である「Stable Diffusion」に加えて2024年8月に登場して一世を風靡している「FLUX.1」も利用可能であり、凝った画像の生成に強みがあると言えます。
基本的に無料で利用できるため、興味があるならばまずはアクセスしてみると良いでしょう。
運営組織について
TensorArtは2023年にリリースされたサービスですが、運営組織情報はLinkdInなどにも公開されておらず詳細は不明です。
とはいえ、プライバシーポリシーや利用規約に明らからな違和感は無いように見受けられたので、少なくとも無料で利用する分には支障も無いでしょう。
アクセス&アカウント登録方法
TensorArtの利用にはアカウント登録が必須です。
1. WebブラウザからTensorArtにアクセスする
任意のWebブラウザからhttps://tensor.art/にアクセスし、画面右上の「Sign in」をクリックします。
2. ログイン方式を選択する
任意のログイン方式を選択します。
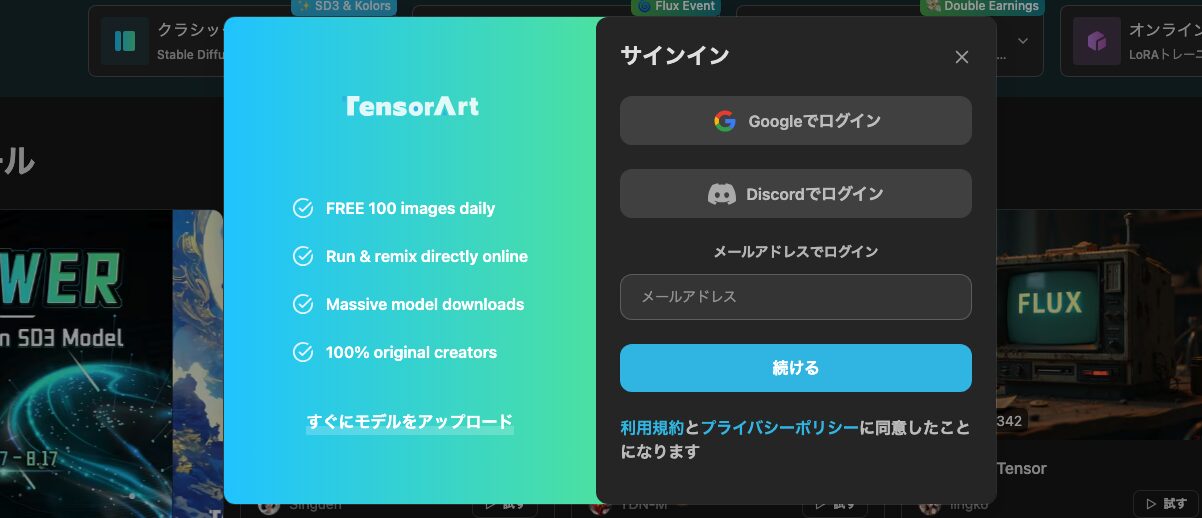
2024年8月時点で選択可能なログイン方式は以下の通りです。
- Googleアカウント連携
- Discordアカウント連携
- Eメールアドレス&パスワード認証
3. ログインできていることを確認する
トップページ右上の「Sign in」が消え、マウスオーバー時にアカウント情報が表示されていればログインは正常に完了しています。
初回ログイン時点では無料プランに属しており、毎日使い切りの100クレジットが手に入ります。
利用料金について
無料でも基本的な機能はおおよそ利用可能ですが、短時間でより多くの画像を生成したい場合や画像の質を高めたい場合はサブスクリプションへの登録を検討してもよいでしょう。
上部メニューに表示されている「Pro」ボタンをクリックすると以下のようなラインナップが表示され、登録が可能です。
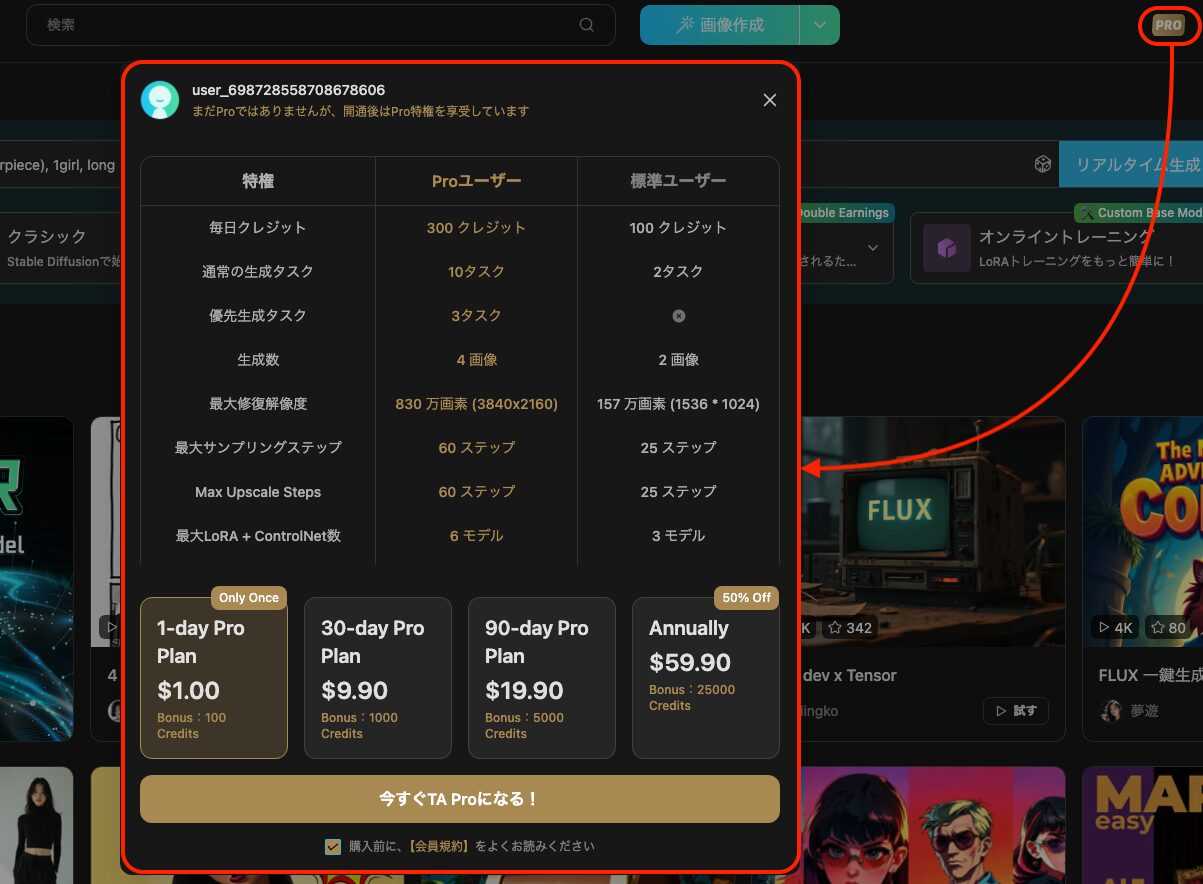
サブスクリプション登録で解禁される要素は以下の通り。
- 毎日のクレジット入手量が増加
- 同時生成タスク数が増加
- 生成速度増加
- 生成数増加
- 選択できるアップスケール倍率の増加
- 選択できるサンプリングステップの最大値が増加
- 選択できるアップスケールステップが増加
- LoRAとControlNetの選択可能数が増加
- 画像の保持期間が2ヶ月に延長
- プライベート(非公開)設定が可能
- 1日の投稿限度が2倍
- 並行トレーニングタスク数が2倍
至れり尽くせりな内容です。1回だけ購入可能な1日限りの「1-day Pro Plan」がお求めやすい価格となっているため、ある程度TensorArtの操作に慣れてきたあたりで今後も継続利用するか迷うようであれば課金してみるのも悪くないかもしれません。
なお、クレジットだけであれば「私のクレジット」メニューから直接購入したりタスク消化で獲得することも出来ます。
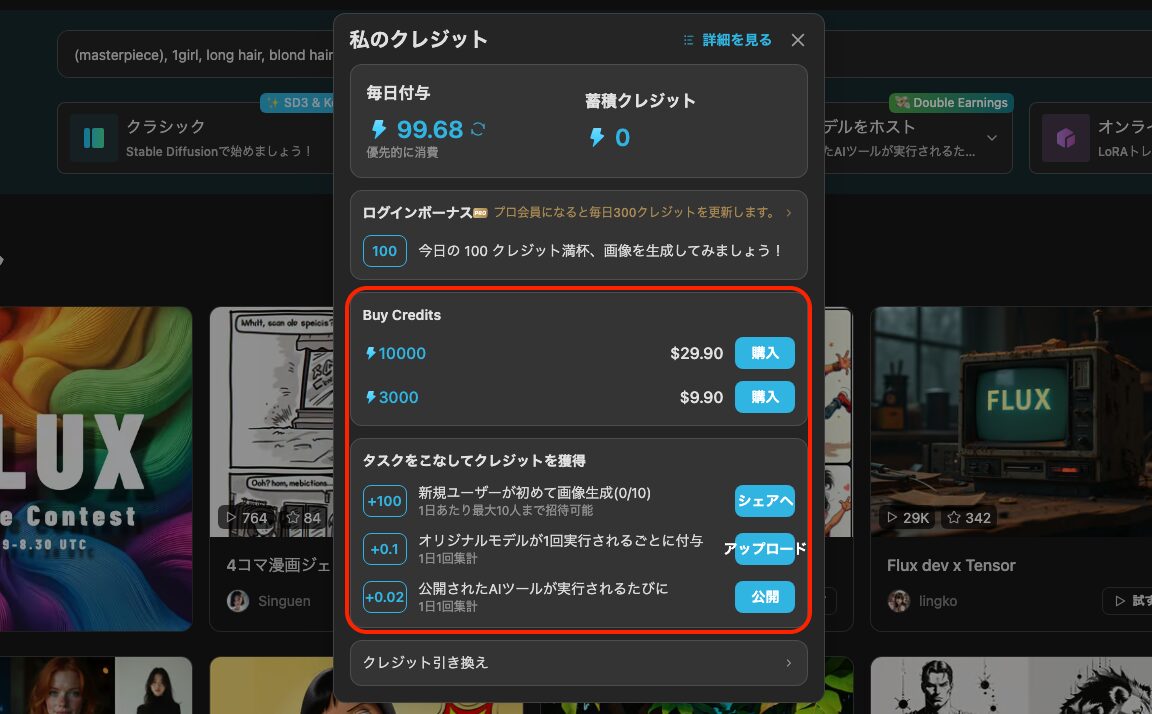
TensorArtの使い方
作成モードには一般的なUIの「クラシック」とノードベースUIの「ワークフロー」の2種類のモードがありますが、生成されるものに大差は無いのでここでは「クラシック」に絞って説明をします。
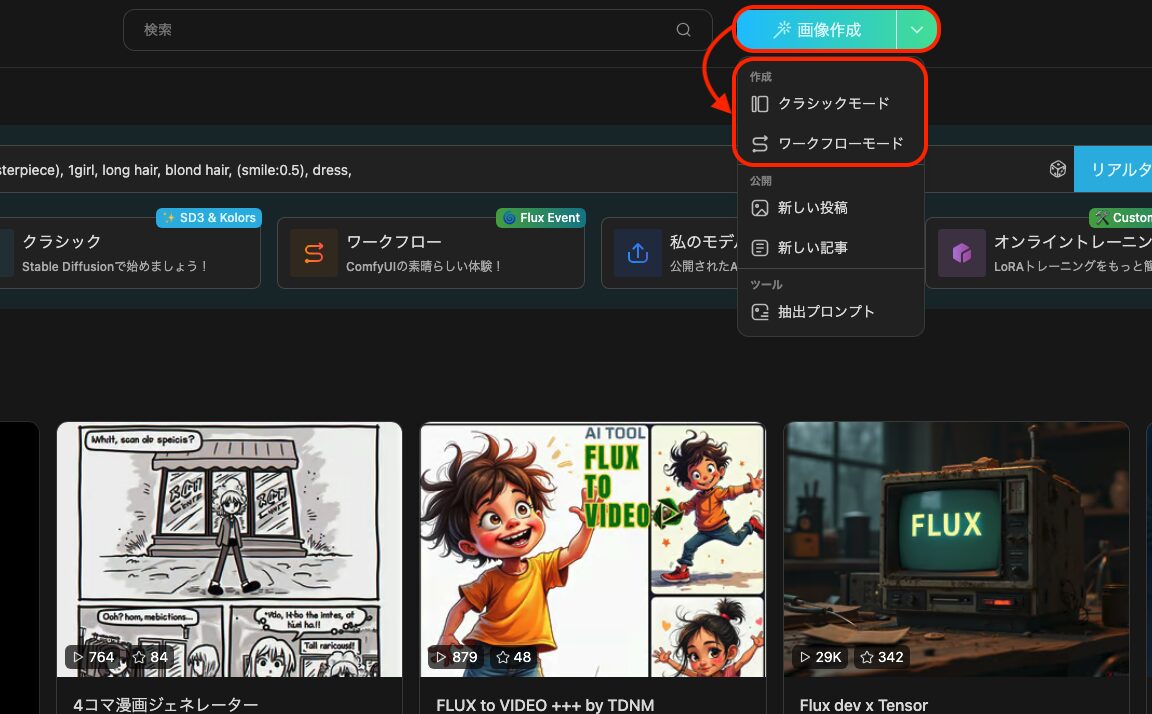
ここから「クラシックモード」を選択
テキストから画像を生成する
クラシックモードから「Text2Img」タブを選択すると、テキストから画像を生成することが出来ます。
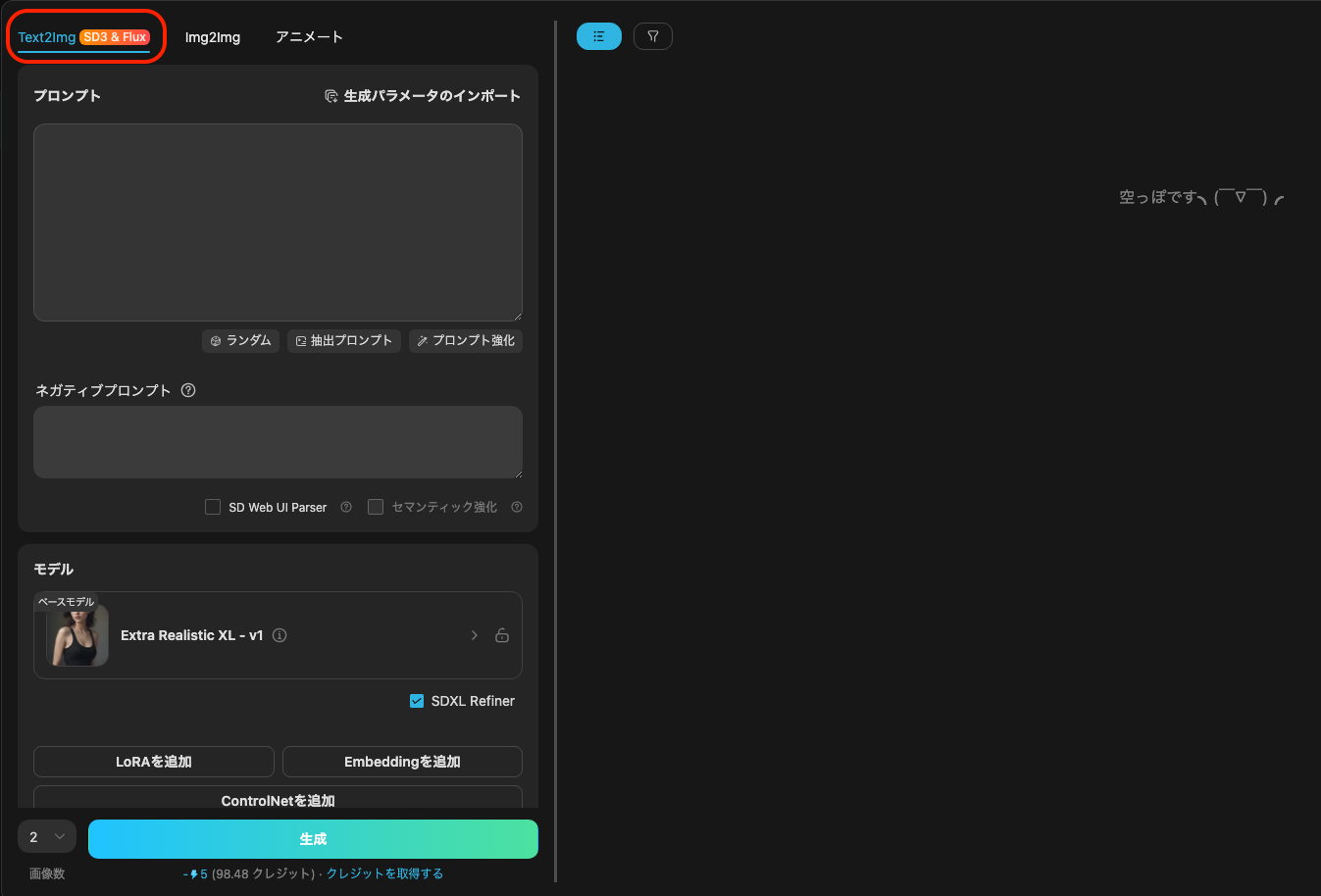
基本的にはプロンプトに生成したい画像の説明を英語で入力し「生成」ボタンをクリックすると、一定のクレジットを消費して画像が生成されます。
…が、それだけだときっと思うような画像を生成するのは難しいと思うので、設定項目を上から順番に説明していきます。
「プロンプト」
生成したい画像を文字で説明する部分です。最も重要な部分。
| 項目名 | 説明 |
|---|---|
| プロンプト | 生成したい画像の説明。基本的には生成したい要素をカンマ区切りで羅列していく。対応言語は英語のみ。 慣れないうちは適当な単語を入力して「プロンプト強化」をクリックすると良いでしょう。凄く詳細な内容で加筆される。 |
| ネガティブプロンプト | 画像に含めたくない要素の説明。こちらも複数の単語をカンマ区切りで羅列していく。 本来であれば色々な単語を入れていくものですが、TensorArtであれば「negativeXL_D」(頻出単語の詰め合わせ)と入力しておけばまずは大丈夫。 |
| SD Web UI Parser | 画像解析手法の選択。未チェックだとTAMS 2.0を使用。 チェックを入れても入れなくても生成される画像の傾向はそれほど変わらないのでお好みで。 |
「モデル」
画像の元となる「モデル」や画像を拡張する「LoRA」などを選択する部分です。慣れないうちは「ベースモデル」を色々変えてみるところから始めましょう。
| 項目名 | 説明 |
|---|---|
| ベースモデル | 画像のベースとなるモデル。またの名をCheckpoint 1種類だけ選択可能。 選択したモデルによってはネガティブプロンプトやサンプリングなどに関する推奨設定が用意されており、自動で設定してくれる場合もある。 |
| LoRA | モデルに追加する要素。特定の用途に絞ったものが多い。 |
| Embedding | Stable Diffusionにおける意味はネガティブプロンプトの詰め合わせ。 自分で作成したEmbeddingを追加することが出来るようですが、最近のモデルを選択するとそもそも対応していないと言われたりする。 |
| ControlNet | 画像の構図やポーズ、カラーなどの指定。 利用する場合は別途CotrolNetを作成しアップロードする必要がある。 |
| VAE | 画像の品質を上げるエンコーダー。カメラにおけるフィルターのようなもの。 |
「設定」
画像のサイズや生成方式などを設定する部分です。
| 項目名 | 説明 |
|---|---|
| 画像サイズ | 生成する画像のサイズ。 決まったサイズから選択するほか、幅や高さを自由に指定することも出来る。 |
| サンプリング法 | AIによる画像生成の方式。 基本的に「DPM」系は高品質な画像が生成されやすいですが、モデルによって利用可能なサンプリング法は異なる。 |
| サンプリング回数 | 画像生成における処理数。数値が高いほど描写が細かくなるが処理時間も増える |
| プロンプト関連度(CFG Scale) | 画像生成に対するプロンプトの反映割合。 数値が高いほどプロンプトの内容が反映されやすくなるが、高すぎると逆に画像が安定しなくなる。 3〜15の範囲が良いらしい。 |
| シード値 | 最終的に生成される画像の傾向。シード値が変わると画像の構成・構図も変わる |
| Clip Encoder | CLIPと呼ばれるテキスト/イメージエンコーダーの指定。 プロンプトを画像生成AIが認識できる形に変換するためのものですが、一概にどれが良いというものでも無いようで、指定はお好み。 |
| クリップスキップ | プロンプト関連度のようなもので、数値が小さいほどプロンプトとの乖離も小さくなる。 1〜2が推奨とのこと。 |
| ENSD | ノイズを制御する設定。0か31337を設定するのが主流らしい。 |
「Upscale」
アップスケール(高解像度化)や画像の修正に関する部分です。
| 項目名 | 説明 |
|---|---|
| 拡大率 | 画像の解像度。 |
| 修復方法 | 生成される画像の修復方法。 写実的な画像向けやアニメ画像向けなど、方法によって得意とする画像の傾向がある。 |
| 高解像度修復サンプリング回数 | 画像生成における処理数。数値が高いほど描写が細かくなるが処理時間も増える |
| デノイズの強さ | 修復の度合い。 数値が高いほど修復内容が強く反映され、結果的に元の画像からかけ離れたものが生成される割合が高くなる |
ADetailer顔面修復
人の顔や手など、一般的に綺麗に生成されにくいとされる部位に関する修復の設定です。モデルによっては選択不可。
| 項目名 | 説明 |
|---|---|
| ADetailerモデル | 修復の対象領域を選択。顔(face)、手(hand)、全身(person)に対応した複数のモデルから1つ選択可能 |
| ADetilerプロンプト | 修復箇所に対する追加のプロンプト |
| ADtailerネガティブプロンプト | 修復箇所に対する追加のネガティブプロンプト |
| 検出モデルの信頼度のしきい値 | 生成画像に対する修復判定箇所のしきい値。 数値が低いと検出される範囲が狭くなり、数値が高すぎると意図しない箇所も修復対象とみなされる傾向にある |
| インペイントマスクのぼかし | エッジフェザリングの強度。 数値を小さくするほど境界線がシャープになる(輪郭がぼやけなくなる) |
| デノイズの強さ | 修復の度合い。 数値が高いほど修復内容が強く反映され、結果的に元の画像からかけ離れたものが生成される割合が高くなる |
| マスク部分のみインペイント | マスクした部分のみを修復の対象とする設定…だと思いますがText2Imgでこの機能が有効なのかは不明 |
Layer Diffusion
生成された画像から背景を削除・透過する設定です。モデルによっては選択不可。
| 項目名 | 説明 |
|---|---|
| Weight | Layer Diffusionの効きの強さ。 0.1〜2.0の範囲で指定でき、数値が大きいほど効きが強くなる。体感的には0.6〜1.0ぐらいが丁度よい。 |
以上の設定をあれこれ弄りつつ最終的にはTensorArt上で公開されている画像を参考にして生成してみたものが以下。

私は公開情報を参考にしましたが、自力で設定を考えて生成できるようになれば上級者だと思います。
ちなみに、生成した画像は何回でもダウンロード出来ますが無料プランだと2週間で削除されてしまうため、気に入った画像があれば忘れる前にダウンロードしておきましょう。
画像から画像を生成する(バリエーション生成)
クラシックモードから「Img2Img」タブを選択するか、または生成画像をマウスオーバーした際のメニューから「img2imgに送る」を選択することで、対象の画像を元にして別の画像を生成することが出来ます。
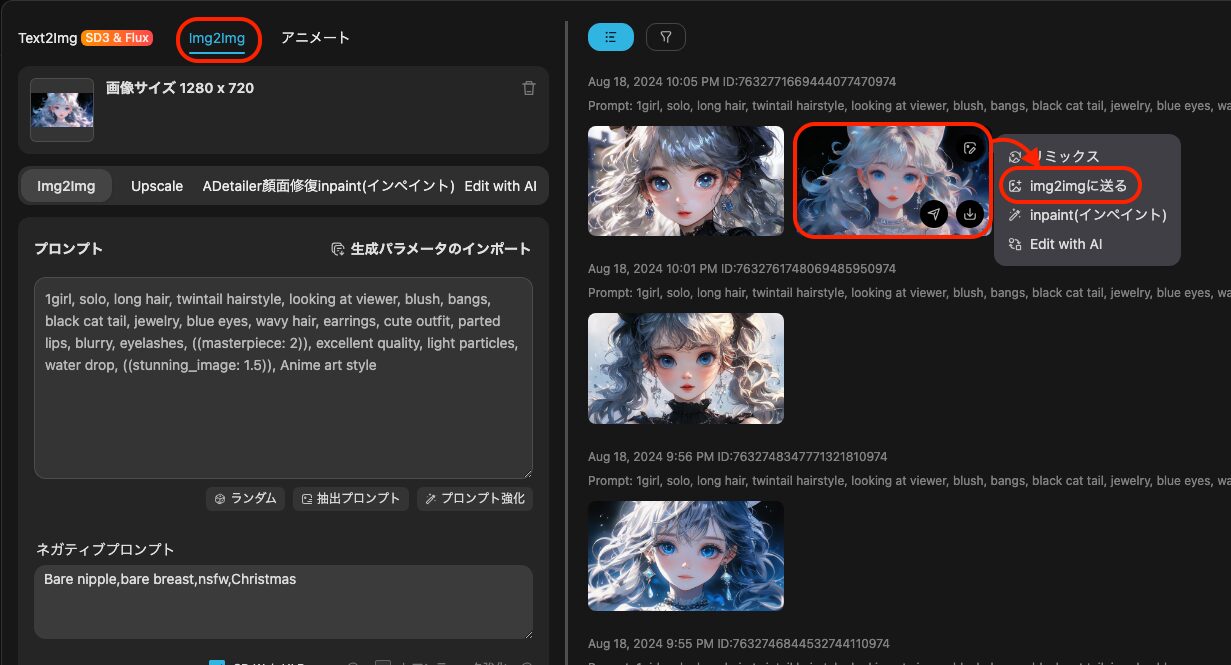
| 項目名 | 説明 |
|---|---|
| Img2Img | 元の画像の特徴(構図など)を維持しつつ別の画像を生成。 |
| Upscale | 解像度の向上。Text2Imgにあったものと同様。 |
| ADetailer顔面修復 | 人の顔や手など、一般的に綺麗に生成されにくいとされる部位に関する修復の設定。 こちらもText2Imgに同様の設定あり。 |
| inpaint(インペイント) | 任意の範囲を指定し別のプロンプトで上書きする。 |
| Edit with AI | プロンプトに記載した内容をAIが解釈して修正を行う…はずですが精度は微妙です。 |
それでは、上記のうち「Upscale」と「ADetailer顔面修復」を除く3種類について、Text2Imgで生成した画像を使って実際に試してみましょう。
なお、Text2Imgと同じく設定項目に応じてクレジットが消費されます。
Img2Img
プロンプトを少し変更してみます(差分は赤文字)
■元のプロンプト
1girl, solo, long hair, twintail hairstyle, looking at viewer, blush, bangs, black cat tail, jewelry, blue eyes, wavy hair, earrings, cute outfit, parted lips, blurry, eyelashes, ((masterpiece: 2)), excellent quality, light particles, water drop, ((stunning_image: 1.5)), Anime art style■修正したプロンプト
1girl, solo, short black hair, twintail hairstyle, looking at viewer, blush, bangs, black cat tail, jewelry, red eyes, wavy hair, cute outfit, parted lips, blurry, eyelashes, ((masterpiece: 2)), excellent quality, light particles, water drop, ((stunning_image: 1.5)), Anime art style
生成結果は以下の通り。完璧ではないですが概ね想定通りの結果となりました。

inpaint(インペイント)
以下のように再生成したい箇所を塗りつぶし、プロンプトに生成させたい内容を記載します。
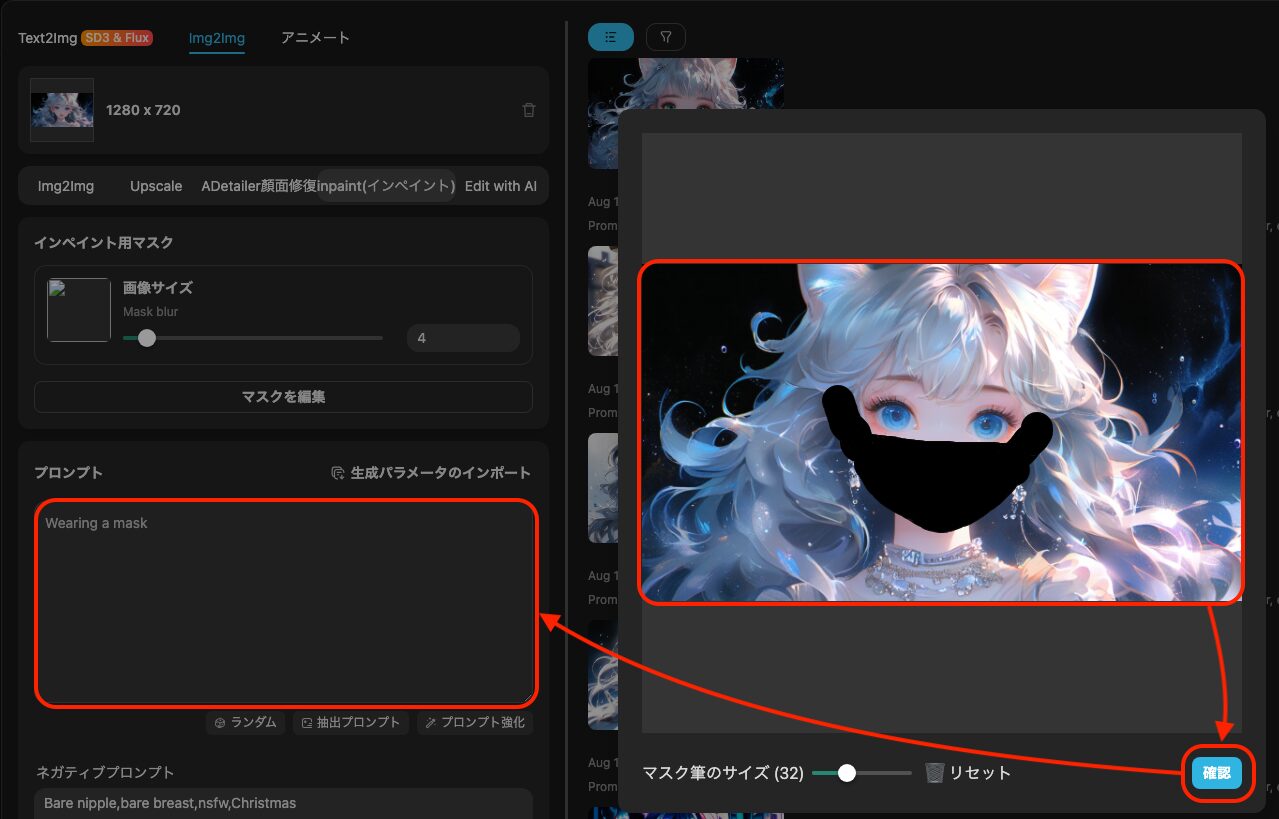
今回は口元を塗りつぶし、プロンプトに「Wearing a mask」(マスクを付けている)と入力しました。結果は以下。

これで風邪を引いても大丈夫ですね(?)
Edit with AI
編集したい内容をプロンプトに直接入力します。試しに以下の内容をプロンプトに入力してみました。
Change eye color from blue to green
(日本語訳)
目の色を青から緑に変更
生成結果は以下の通り。

どうして…?
目の色どころか全体的に緑色になってしまいました。AIの発想力には驚かされるばかりです。
テキストから動画を生成する
クラシックモードから「アニメート」タブを選択すると、テキストから1秒の動画(gif形式)を生成することが出来ます。
使い方は「Text2Img」とだいたい同じであり、プロンプトに生成したい動画の説明を英語で入力し「生成」ボタンをクリックすると、一定のクレジットを消費して画像が生成されます。
設定可能な項目もText2ImgやImg2Imgと概ね同じですが、以下のような違いはあります。
- 選択可能なモデルやLoRAが異なる
- 修復関連の項目はない
- アニメート特有の設定項目(フレーム数、FPS)がある
また、消費クレジットは画像生成と比べて遥かに大きく、例えばフレーム数を16、サンプリング回数を20とした場合は生成1回につき約13クレジットを消費します。
というわけで試しに生成してみたものが以下。
設定内容(主要項目抜粋)
■プロンプト
Close-up of a girl with silver hair and blue eyes. She is wearing shiny earrings and has a gentle smile on her face.■ネガティブプロンプト
EasyNegative■モデル
RealCartoon – Special SP1■MotionLoRA
v2_lora_ZoomOut – 1
生成結果

1秒なので使い道は限られそうですが、一応動画の生成も出来るよってことで。
使用した感想
設定項目が非常に多く理想の画像を生成するには慣れが必要ですが、使いこなせるようになると一気に表現の幅が広がるようには思えました。というかこれもうStable Diffusionそのものですね。
類似サービスのSeaArt AIとは好みで使い分ければ良いというか、むしろ両方のアカウントを作成してより多くの生成経験を積むことが最良かと思われます。










