
VIVAGO(ビバゴー)はWebブラウザで利用可能な画像・動画生成サービスです。
OpenAI社が発表し界隈が震撼した動画生成AIであるSora…を彷彿とさせるクオリティの動画を生成させることが出来るのが特徴と言えます。
基本的な機能は無料で利用できるため、興味があるならアクセスしてみると良いでしょう。
運営組織について
VIVAGOは2023年に中国・北京にて設立された「北京智象未来科技有限公司」と、関連する企業またはサービスである「HiDream.ai」によって運営されているサービスです。
「北京智象未来科技有限公司」および「HiDream.ai」の日本国内における情報展開がほぼ無いため詳細は不明ですが、AIGC(AI-Generated Content)の研究・開発に強みがあるようで、実際に生成された動画や画像を見てもレベルが高い印象を受けます。
アクセス&アカウント登録方法
VIVAGOの利用にはアカウントの登録が必須です。Webサイトへのアクセス方法から順に説明していきましょう。
① vivago.aiにアクセスする
任意のWebブラウザからvivago.aiにアクセスし、画面左下か右上の「TRY FOR FREE」をクリックします。
② 登録画面に移動する
メインページ(Explore画面)に遷移したら画面右上の「Login/Register」をクリックします。
③ ログイン方式を選択する
ログイン画面がポップアップしたら任意のログイン方式を選択します。
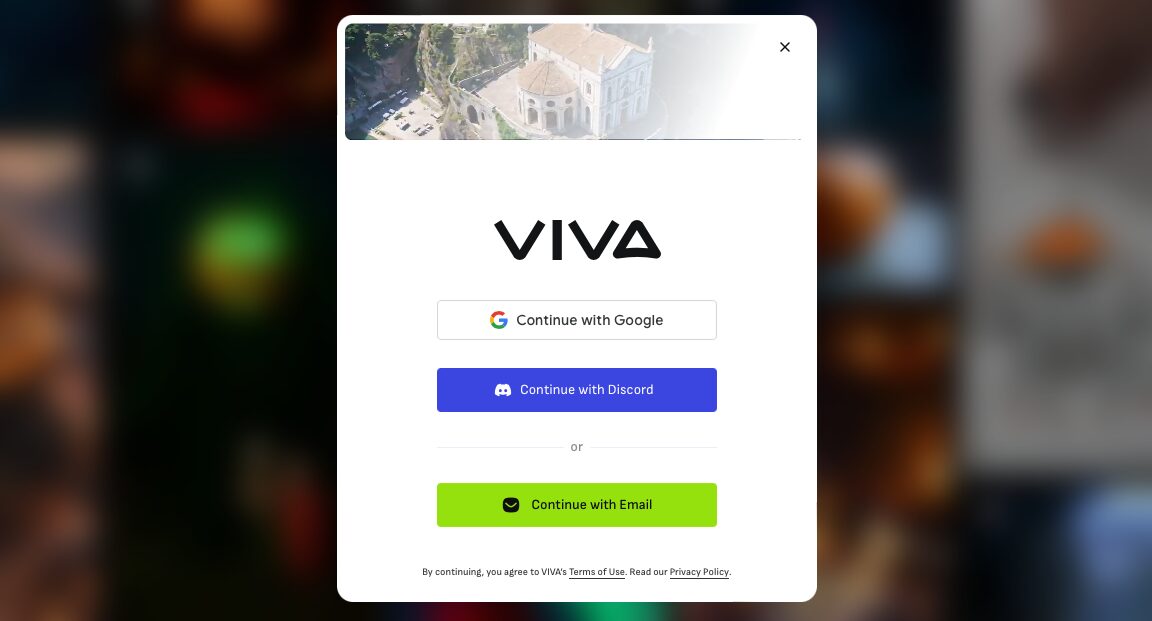
2024年12月時点で選択可能なログイン方式は下記の通り。
- Googleアカウント連携
- Discordアカウント連携
- Eメールアドレス認証
④ ログインされていることを確認する
メインページに遷移後、画面右上の表示が「Login/Register」からアカウントアイコンに変わっていればログインは正常に完了しています。
利用料金について
無料プランでも大体の機能は利用できますが、高品質な生成モデルの利用や生成効率を上げたい場合はサブスクリプションの登録を検討しても良いでしょう。
画面上部の「Subscribe」をクリックすると以下のようなラインナップが表示され、そのまま登録が可能です。
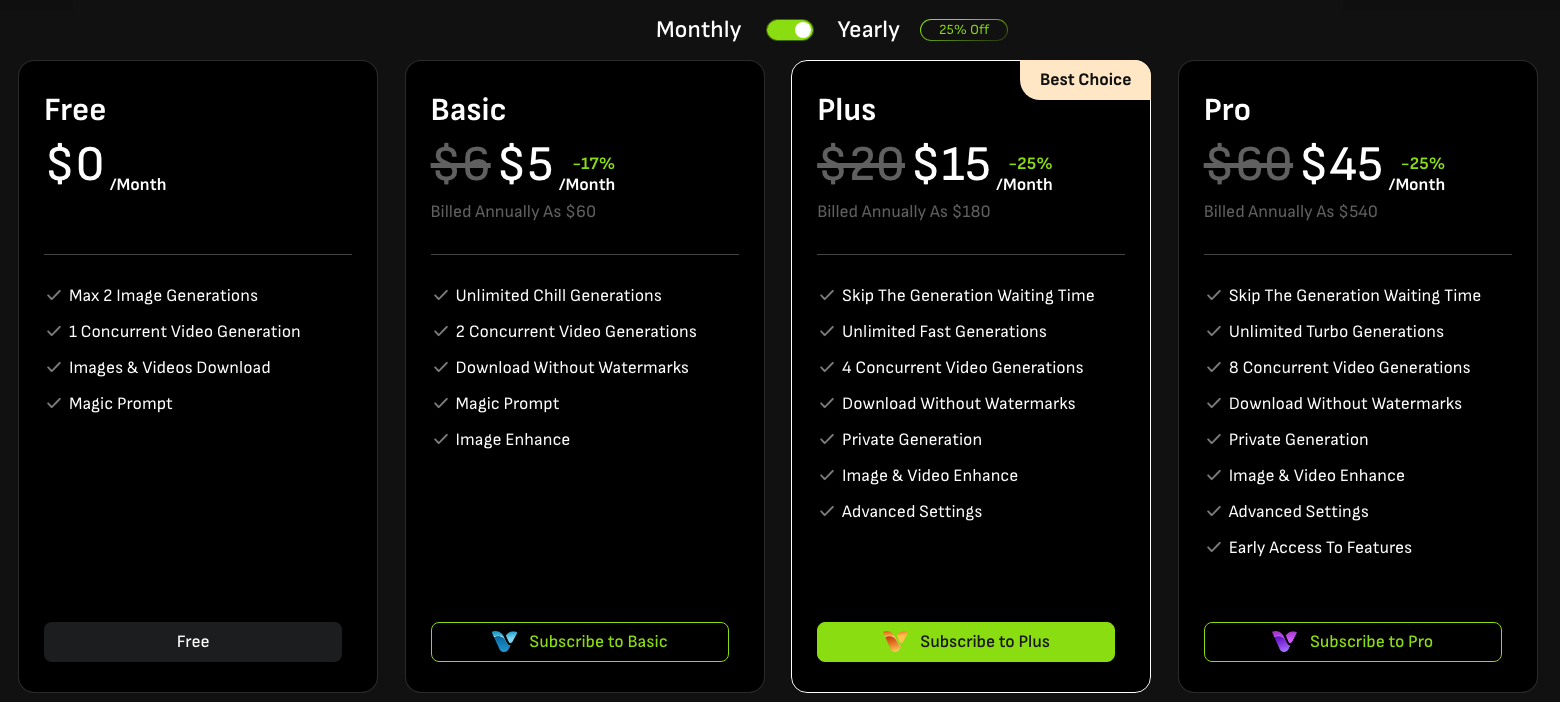
年間契約だと20%OFF
サブスクリプションの登録により解禁される要素は以下の通り。
- 1日の動画/画像生成数の制限撤廃
- 同時生成数の増加
- 透かしの削除
- 生成速度の加速(待ち時間のスキップ)
- 画像/動画のエンハンス(アップスケール)が可能
- プライベート生成が利用可能
- 高度な設定を利用可能
なお、サブスクリプション登録の有無に関係なく商用利用は可能ですが結果として他者の権利を侵害するようなことは明確に禁止されています(当たり前)
要は著作権や肖像権を侵害しないように配慮しましょうということです。
VIVAGOの使い方
メインページ左側のメニューにある「TOOLS」より各種生成サービスを選択・利用することが可能です。
ここでは主要な機能(動画/画像生成)にフォーカスを当てて使い方を説明していきます。
テキストから動画を生成する
「Video Generation」内の「Text to Video」ではテキストから動画を生成することが出来ます。
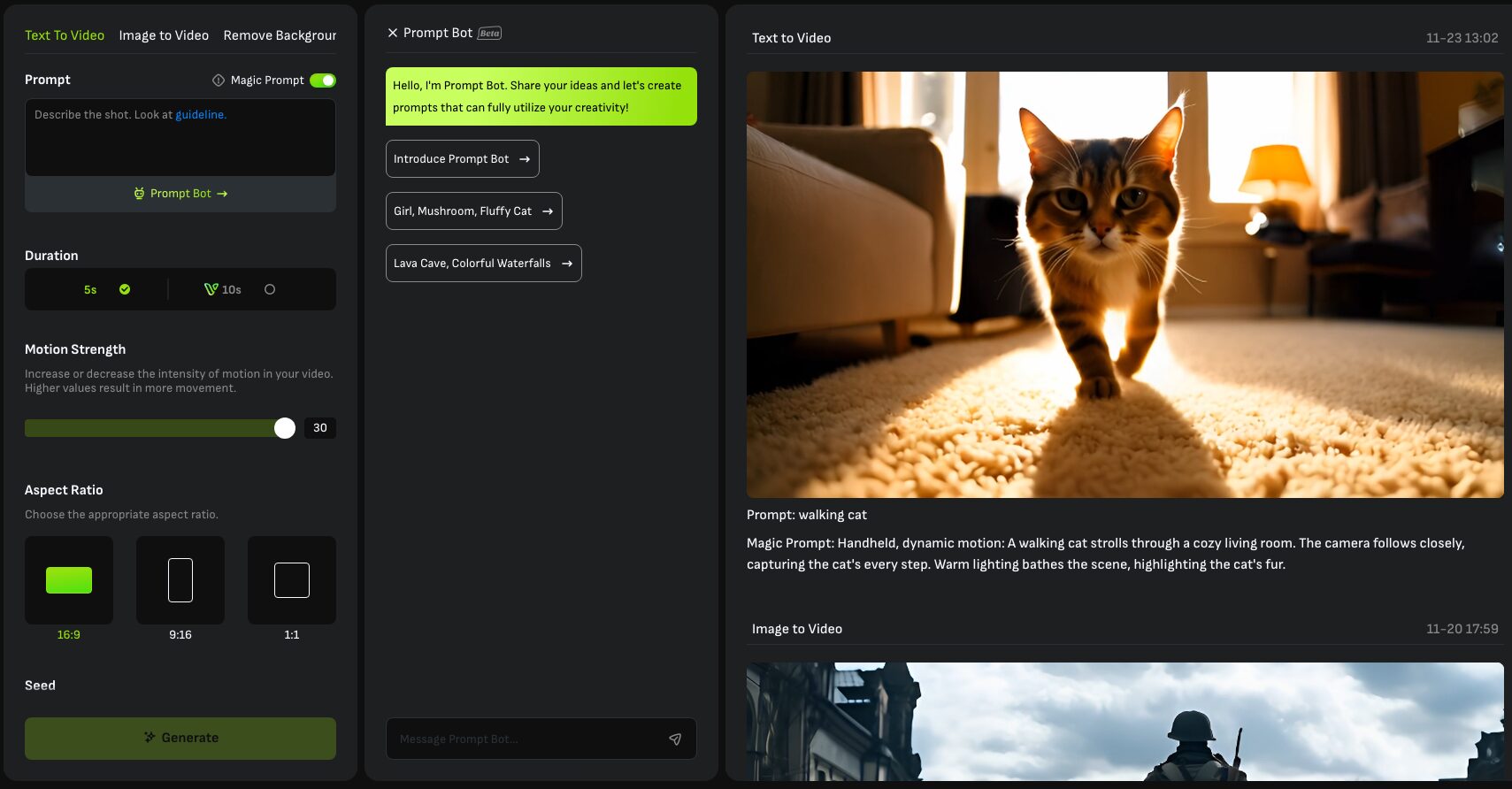
ねこ
生成方法は以下の通りです。
① プロンプトを入力する
「Prompt」から動画にしたいシチュエーションなどを英語で入力します。
おおよその動画生成AIで採用されていますが構文の基本は「主題」+「主要要素」であり、単純に言えば普通の英語です。簡単な例だと以下のような内容がプロンプトの基本です。
Japanese office worker drinking beer in the office.
(日本のサラリーマンがオフィスでビールを飲んでいる)
また、プロンプト入力の際に「Magic Prompt」を有効化していると入力されたテキストをAIが添削し、動画生成時により詳細なプロンプトに書き換えます。
例えば上記のプロンプトを入力した場合、以下のように改められます。
Close up, static shot: A Japanese office worker, dressed in a suit, sits at a desk cluttered with papers and a computer. He raises a beer can to his lips, taking a sip. Camera focused on his face, capturing the moment of relaxation amidst the busy office environment.
(クローズアップ、静止画:スーツを着た日本の会社員が、書類とコンピュータが散乱した机に座っている。彼はビール缶を唇に近づけ、一口飲む。カメラは彼の顔に焦点を合わせ、忙しいオフィス環境でのリラックスの瞬間を捉えている)
なお、プロンプトのアイデアが思い浮かばない場合は「Prompt Bot」を利用することで適当なキーワードを代わりに入力してくれたりもします。
② 動画の長さを指定する
「Duration」から生成する動画の長さを選択します。
選べるのは「5秒」か「10秒」のいずれかですが、10秒はサブスクリプションに登録していないと選択できません。
③ 動きの強さを指定する
「Motion Strength」から動画自体の動きの強さを指定します。
選択可能な範囲は0〜30までとなっており、数値が高いほどアグレッシブな動画が生成されます。
④ 画像サイズを指定する
「Aspect Ratio」から生成される動画のアスペクト比率を指定します。
選択できる比率は「16:9」「9:16」「1:1」の3種類です。
⑤ シード値を指定する(任意)
「Seed」から動画のシード値を指定することが出来ます。
シード値はざっくり言えば動画の構成などを決める乱数のようなもので、シード値が異なると同じプロンプトを入力した場合でも生成される動画が変化します。
デフォルトは未入力であり、これはシード値がランダムに決まることを意味します。
⑥ ネガティブプロンプトを入力する(任意)
「Negative Prompt」から動画に含めたくない要素を入力することが可能です。
⑦ 動画を生成する
各項目を設定後に「Generate」をクリックすると動画が生成されます。
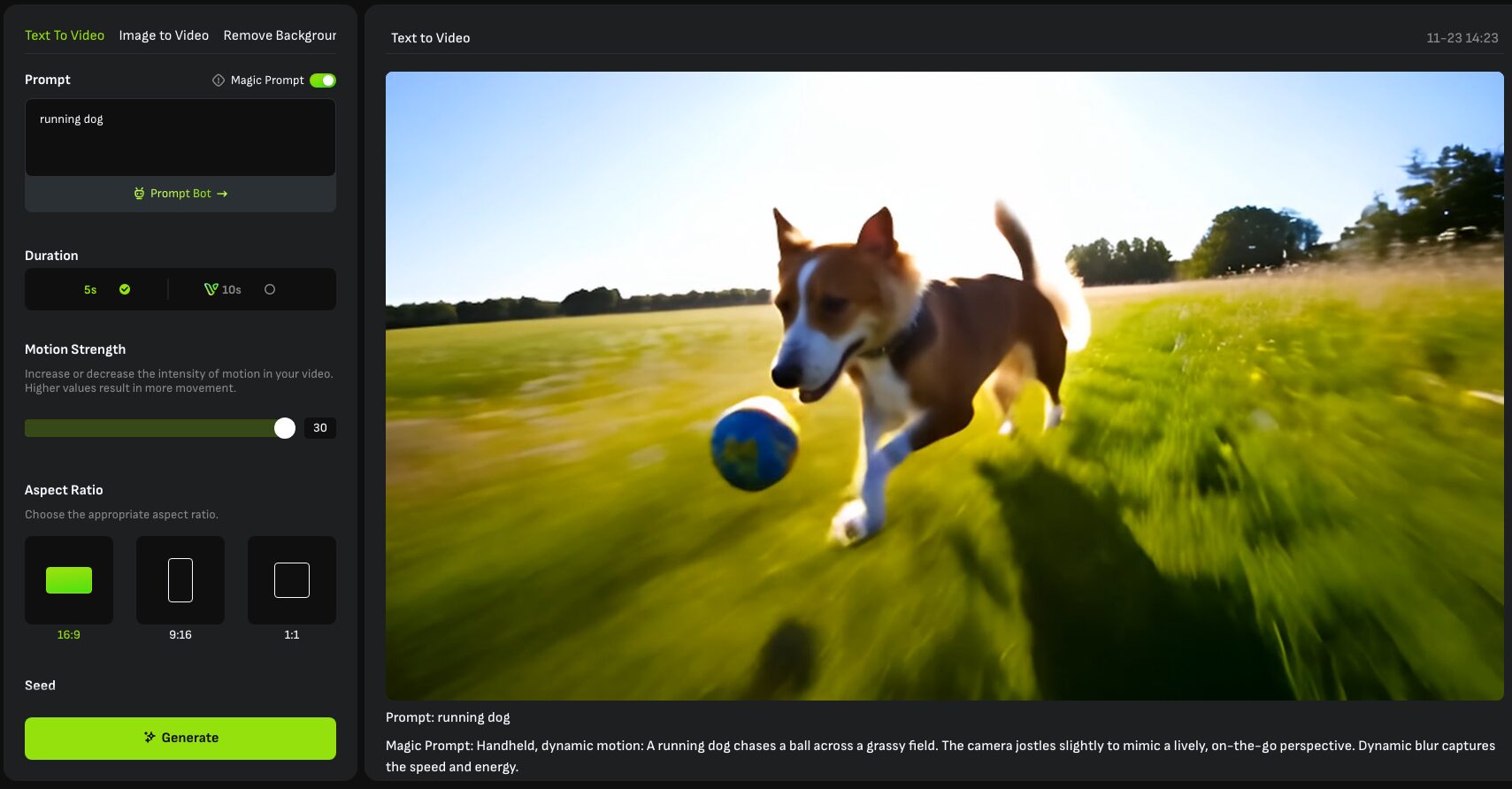
いぬ
また、生成された動画をクリックすると編集画面に移動し、右側のメニューからダウンロードや編集などを行うことが出来ます。
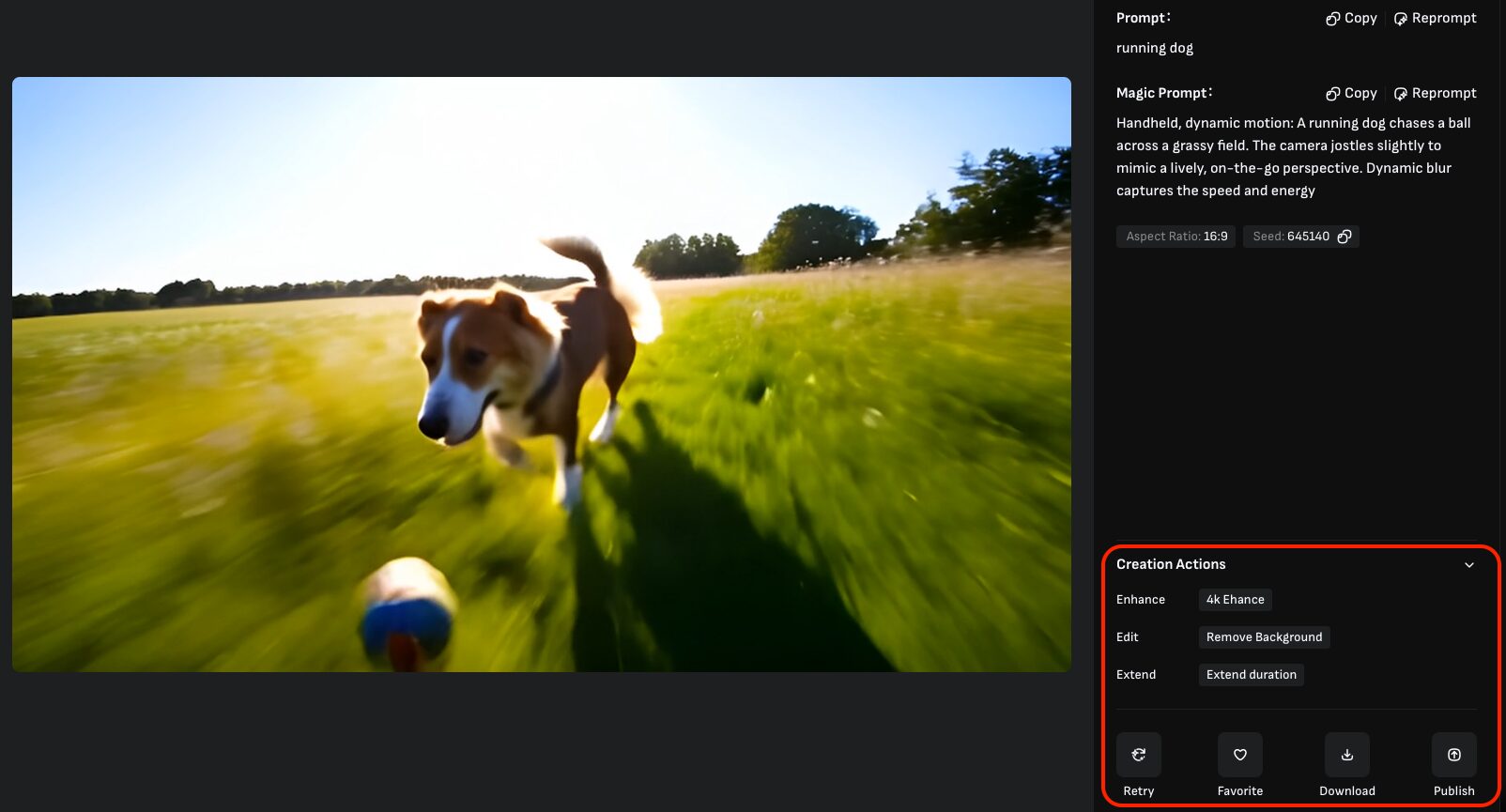
赤枠で囲っている機能の説明は以下の通りです。
| 項目名 | 説明 |
|---|---|
| Enhance | 動画を高解像度化(アップスケール)します。 5秒の動画に対してのみ実施可能であり、Extendされた動画や10秒で生成した動画に対してはEnhance出来ません。 |
| Remove Background | 動画の背景を削除します。 削除可能な動画は人物が明確に映っているものに限定され、また、削除と言っても透過されるわけではなく緑背景(GB)に置き換えられます。 |
| Extend duration | 動画を延長します。 延長時間は元となった動画によって異なり、5秒の動画に対しては+3秒、10秒の動画に対しては+8秒も延長されます。ちなみに延長は複数回実施可能。 なお延長される内容はコントロールできずAIのさじ加減一つとなります。 |
| Retry | 同じプロンプトで動画を再生成します。 |
| Favorite | 動画をお気に入りに追加します。追加された動画は左メニューの「Favorite」から確認可能。 |
| Download | 動画をダウンロードします。 |
| Publish | 動画を公開します。公開された動画はVIVAGOの「Explore」に表示され、他のユーザーから閲覧可能な状態となります。 |
画像から動画を生成する
「Video Generation」内の「Image to Video」では画像から動画を生成することが出来ます。
さっきの犬
生成方法は以下の通りです。
① 画像をアップロードする
「Upload an Image」から動画にしたい画像をアップロードします。VIVAGOで生成した画像を使用する場合は「Select from Assets」から直接選択することも出来ます。
画像のアップロード/選択後、その場でアスペクト比率の指定が求められるので「16:9」「1:1」「9:16」の中から好みの比率を選択し「Cofirm」で確定させます。
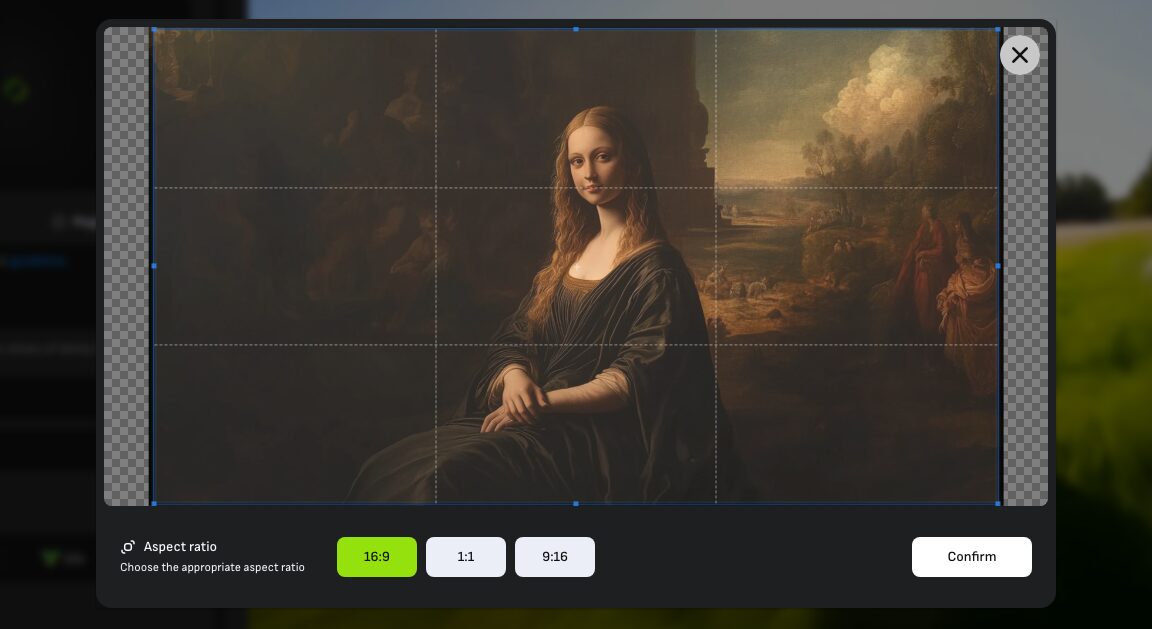
また、「Keyframe」を有効化すると動画の最後のフレームに指定する画像を新たにアップロードすることが出来ます。こうすることで設定した画像に合わせてシームレスに遷移する動画が生成されるため、より意図した動きが作りやすくなるでしょう。
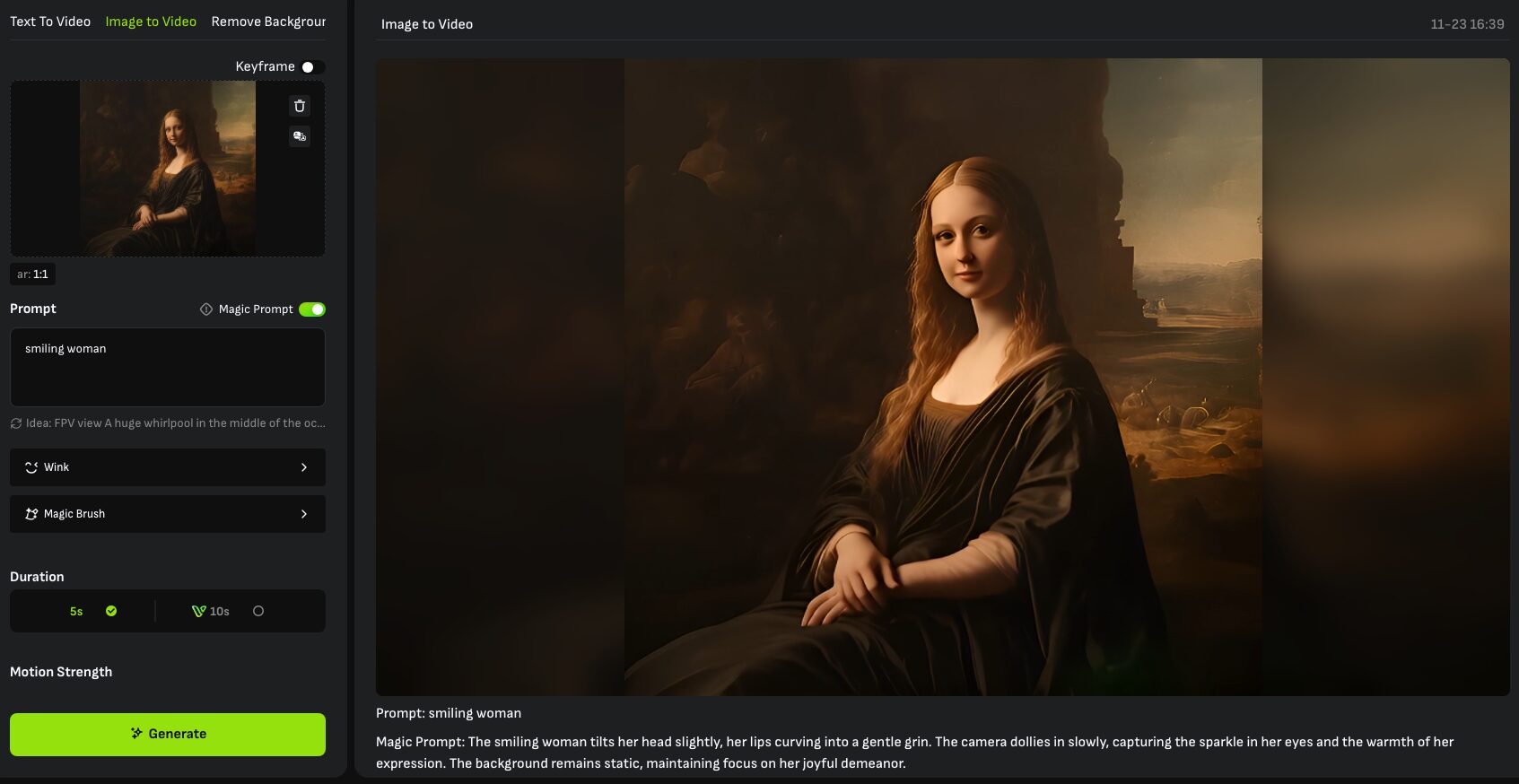
② プロンプトを入力する
「Prompt」から動画にしたいシチュエーションなどを英語で入力します。設定内容は「テキストから動画を生成する」で記載した内容と同様に「主題」+「主要要素」で構成する必要があります。
また、Image to Video独自の機能として顔に特定の動きを付与する「Wink」と、任意の箇所のみを動かす「Magic Brush」が利用できます。それぞれの設定内容は以下の通り。
Wink
表情などを参考にしたい動画をアップロードするか、あらかじめ決まった動きをテンプレートから選択出来ます。
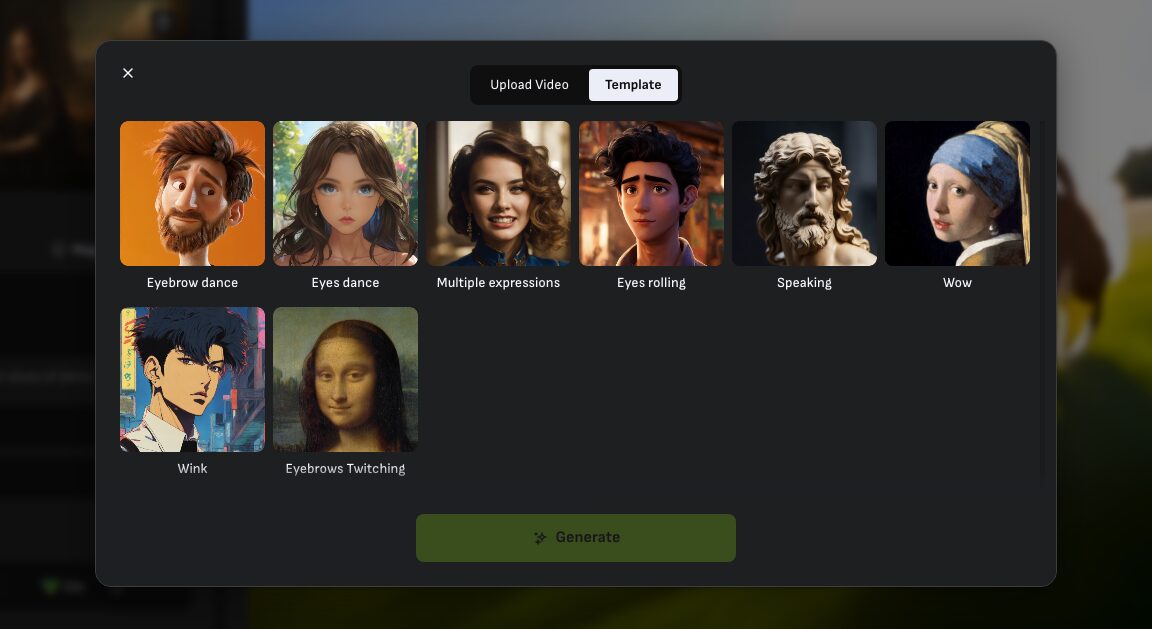
これはテンプレート
動きを選択して「Generate」をクリックすると即座に生成が開始されます。なお、動画時間を含む他の設定は無視されます。
Magic Brush(Plusプラン以上限定)
動かしたい範囲を「Brush」で指定したあと、動かしたい方向を「Motion Track」で指定することが出来ます。
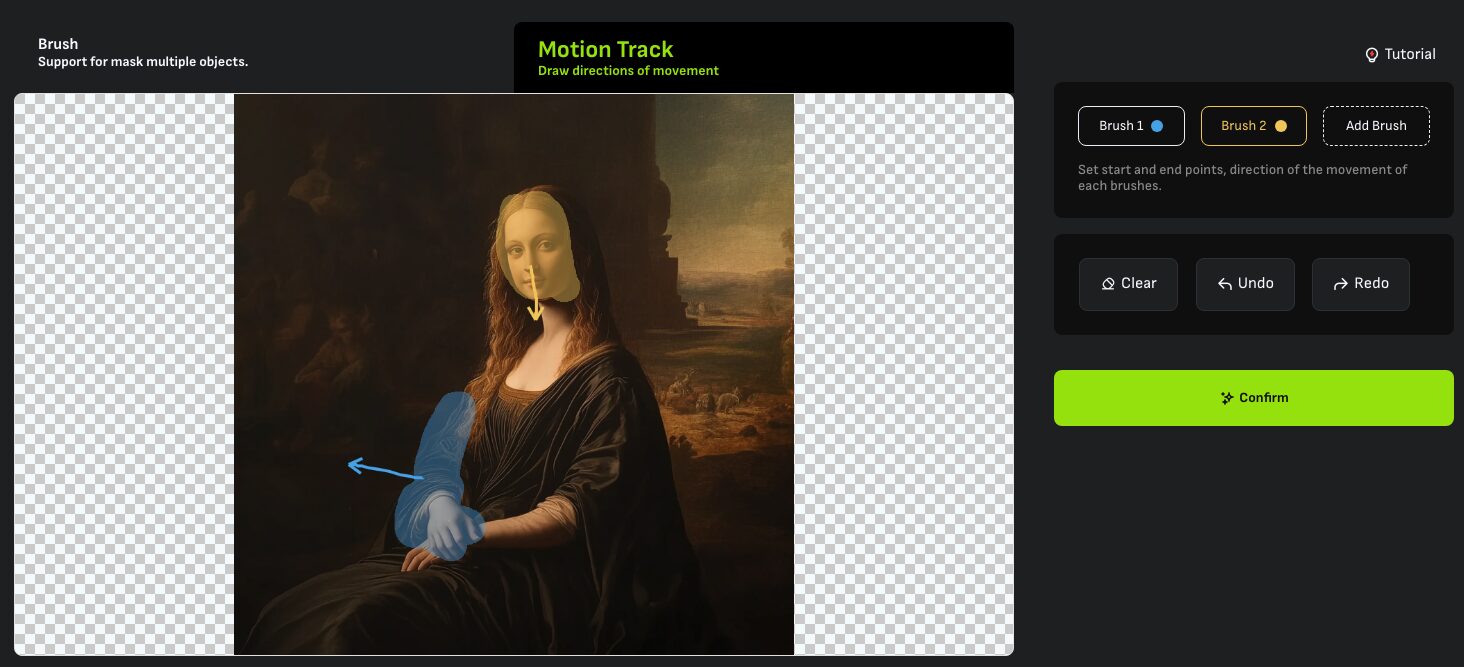
Winkとは異なり、設定後に「Cofirm」をクリックしても即時生成はされずプロンプトや動画時間などの設定を続けて行うことが可能です。
③ 動画の長さを指定する
「Duration」から生成する動画の長さを選択します。
選べるのは「5秒」か「10秒」のいずれかですが、10秒はサブスクリプションに登録していないと選択できません。
④ 動きの強さを指定する
「Motion Strength」から動画自体の動きの強さを指定します。
選択可能な範囲は0〜30までとなっており、数値が高いほどアグレッシブな動画が生成されます。
⑤ シード値を指定する(任意)
「Seed」から動画のシード値を指定することが出来ます。
シード値はざっくり言えば動画の構成などを決める乱数のようなもので、シード値が異なると同じプロンプトを入力した場合でも生成される動画が変化します。
デフォルトは未入力であり、これはシード値がランダムに決まることを意味します。
⑥ ネガティブプロンプトを入力する(任意)
「Negative Prompt」から動画に含めたくない要素を入力することが可能です。
⑦ 動画を生成する
各項目を設定後に「Generate」をクリックすると動画が生成されます。
また、生成された動画をクリックすると編集画面に移動し、右側のメニューからダウンロードや編集などを行うことが出来ます。
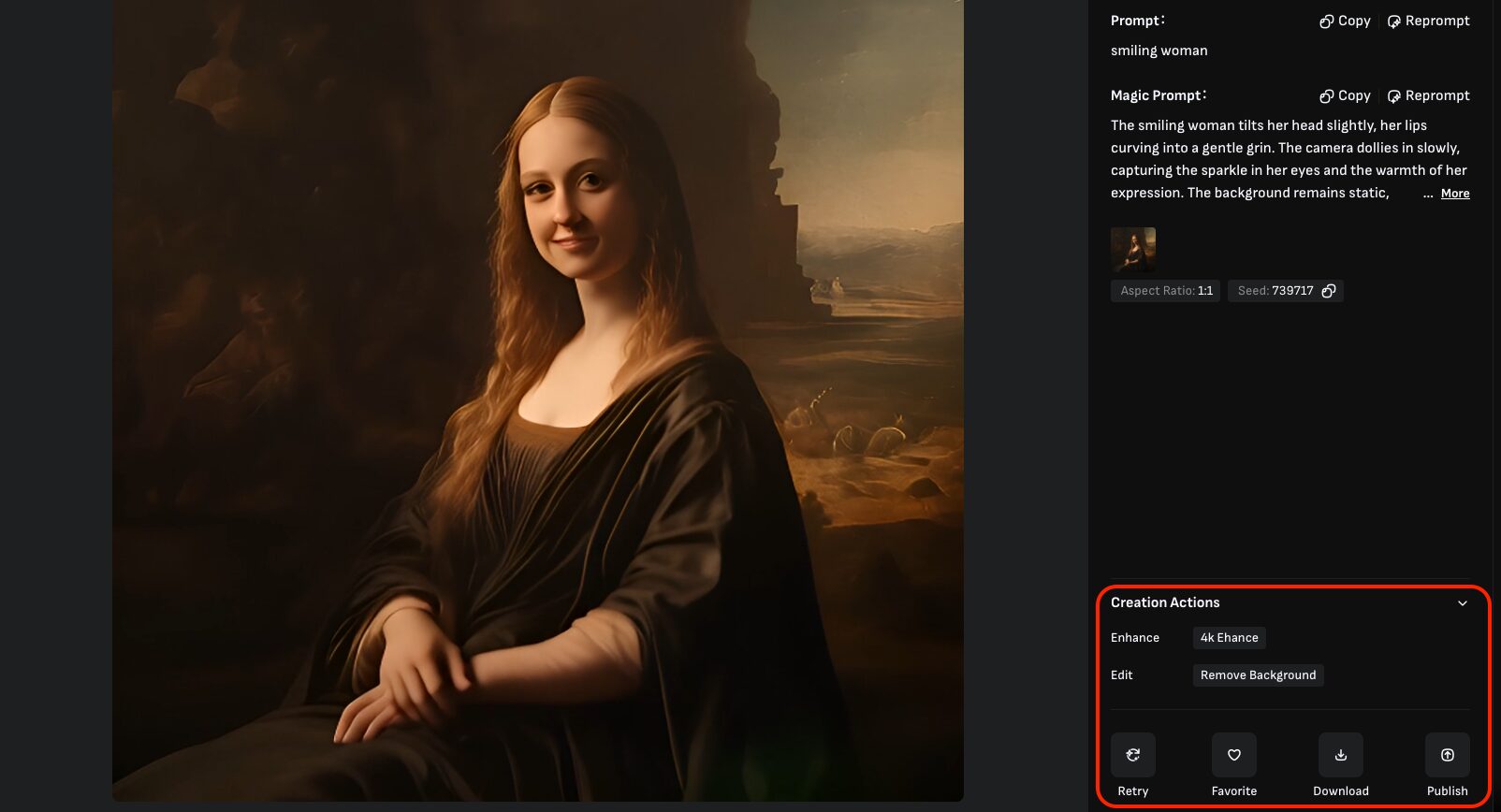
赤枠で囲っている機能の説明は以下の通りです。「テキストから動画生成」と同じ項目に見えますが「Extend」は含まれていません。
| 項目名 | 説明 |
|---|---|
| Enhance | 動画を高解像度化(アップスケール)します。 5秒の動画に対してのみ実施可能であり、Extendされた動画や10秒で生成した動画に対してはEnhance出来ません。 |
| Remove Background | 動画の背景を削除します。 削除可能な動画は人物が明確に映っているものに限定され、また、削除と言っても透過されるわけではなく緑背景(GB)に置き換えられます。 |
| Retry | 同じプロンプトで動画を再生成します。 |
| Favorite | 動画をお気に入りに追加します。追加された動画は左メニューの「Favorite」から確認可能。 |
| Download | 動画をダウンロードします。 |
| Publish | 動画を公開します。公開された動画はVIVAGOの「Explore」に表示され、他のユーザーから閲覧可能な状態となります。 |
テキストや画像から画像を生成する
「Image Generation」からはテキストから画像(Text to Image)、または画像から画像(Image to Image)を生成することが出来ます。
生成方法は以下の通りです。
① プロンプトを入力する
「Prompt」から動画にしたいシチュエーションなどを英語で入力します。
おおよその画像生成AIで採用されていますが構文の基本は「主題」+「主要要素」であり、単純に言えば普通の英語です。
動画生成よりも簡単な英文で問題は無く、究極的には以下のような内容でも正常に生成されます。
A girl
(女の子)
プロンプト入力の際に「Magic Prompt」を有効化していると入力されたテキストをAIが添削し、画像生成時により詳細なプロンプトに書き換えます。
例えば上記のプロンプトを入力した場合、以下のように改められます……が、誇張が過ぎる表現になりがちですね。
A captivating young girl, bathed in soft, ethereal light, stands with a sense of grace and wonder. Her eyes sparkle with curiosity, reflecting the world around her. She is adorned in a simple yet elegant dress, the fabric flowing gently in the breeze. The scene is set in a whimsical forest, with towering trees and vibrant flora, creating a magical atmosphere that encapsulates the spirit of youth and imagination.
(柔らかく幻想的な光に包まれた、魅力的な少女が、優雅さと好奇心を持って立っている。彼女の目は好奇心で輝き、周りの世界を映し出している。彼女はシンプルながらもエレガントなドレスを身につけ、布地がそよ風になびいている。舞台は、そびえ立つ木々と鮮やかな植物が生い茂る、夢幻的な森。若さと想像力の精神を捉えた、魔法のような雰囲気が漂っている)
また、「Tags」には画風やレイアウトなどのプリセットが登録されており任意で複数のタグを選択可能です。
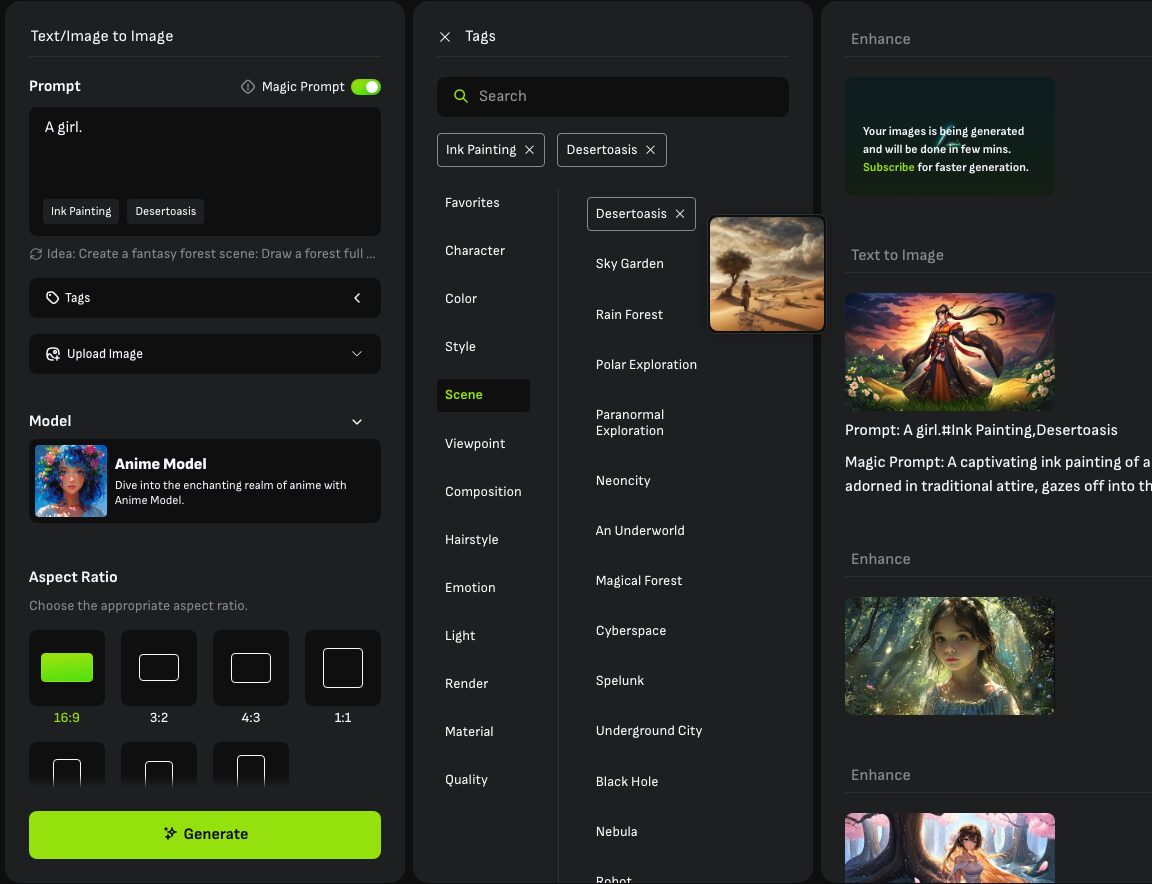
絵のスタイルを指定できる便利機能
さらに、「Upload Image」から手持ちの画像をアップロードすると、アップロードした画像の構図などを参照した画像が新たに生成されます。
② モデルを選択する
「Model」から画像生成に使用するモデルを選択します。
選択可能なモデルはアニメ調の表現が得意な「Anime Model」と、アーティスティックな表現が得意な「Polyart Model」の2種類です。
さらに「Polyart Model」では生成速度を重視した「Express」モードか、品質を重視した「Premium」モードを選択できます。※PremiumモードはBasicプラン以上限定
③ アスペクト比率を選択する
「Aspect Ratio」から生成される動画のアスペクト比率を指定します。
選択できる比率は動画生成よりも多く、「16:9」「3:2」「4:3」「1:1」「2:3」「3:4」「9:16」の7種類から選択できます。
④ シード値を指定する(任意)
「Seed」から画像のシード値を指定することが出来ます。
シード値はざっくり言えば画像の構成などを決める乱数のようなもので、シード値が異なると同じプロンプトを入力した場合でも生成される画像が変化します。
デフォルトは未入力であり、これはシード値がランダムに決まることを意味します。
⑤ 生成枚数を選択する
「Image Count」から生成する枚数を1〜4の範囲で選択します。
⑥ ネガティブプロンプトを入力する(任意)
「Negative Prompt」から画像に含めたくない要素を入力することが可能です。
⑦ 画像を生成する
各項目を設定後に「Generate」をクリックすると画像が生成されます。
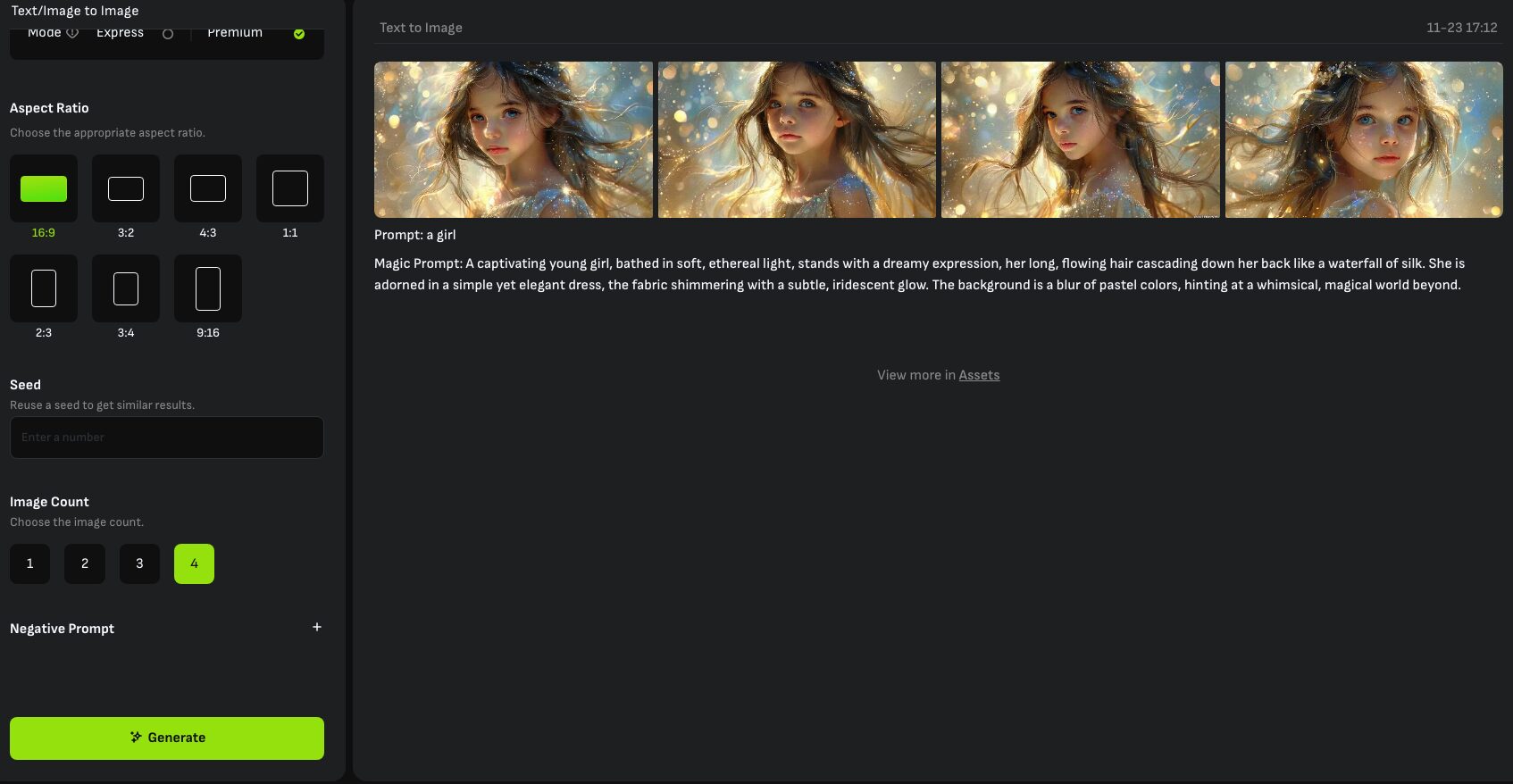
また、生成された画像をクリックすると編集画面に移動し、右側のメニューからダウンロードや編集などを行うことが出来ます。
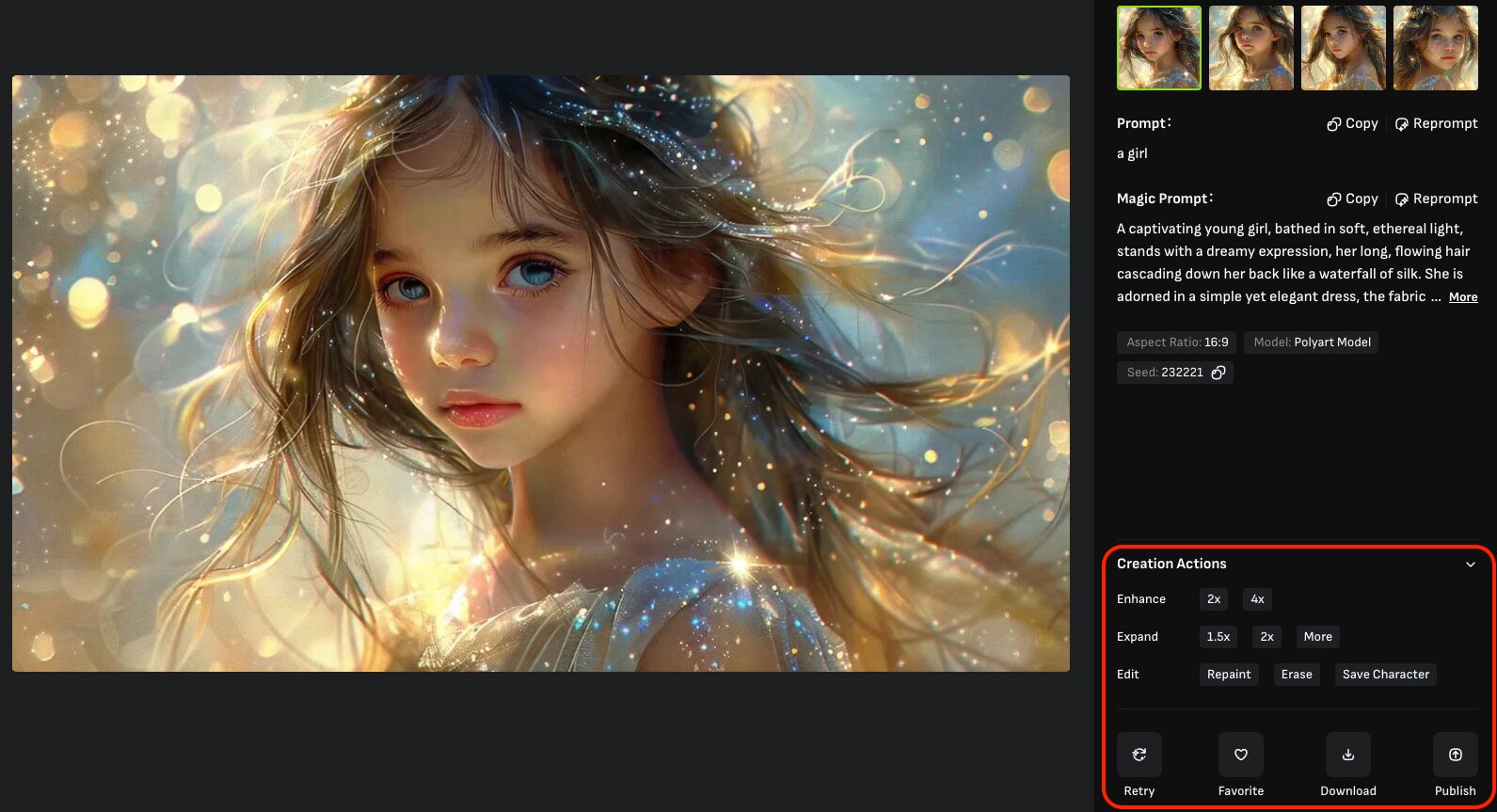
赤枠で囲っている機能の説明は以下の通りです。
| 項目名 | 説明 |
|---|---|
| Enhance | 画像を高解像度化(アップスケール)します。 高解像度化の過程で細部の書き直し等が行われており、基本的には綺麗に仕上がります。 |
| Expand | 画像の描画領域を外側に拡張します。いわゆるアウトペインティング。 |
| Repaint | 画像内の任意の箇所を指定し、別のプロンプトで上書きします。 |
| Erase | 画像内の任意の箇所を削除します。削除された部分はAIが適当な画像に置き換えます。 |
| Save Character | 画像に映っている人物を保存します。 保存されたキャラクターは「Tags」に登録され、画像生成時に参照することが可能です。 |
| Retry | 同じプロンプトで画像を再生成します。 |
| Favorite | 画像をお気に入りに追加します。追加された動画は左メニューの「Favorite」から確認可能。 |
| Download | 画像をダウンロードします。 |
| Publish | 画像を公開します。公開された動画はVIVAGOの「Explore」に表示され、他のユーザーから閲覧可能な状態となります。 |
参考資料
モデルごとの生成結果比較
画像生成では複数のモデルを選択可能ですが、それぞれどのような違いがあるのかを生成結果から比較していきましょう。
使用するプロンプトは共通して以下とし、画像の歪みを補正するためのEnhance 2xを掛けています。特にAnime ModelはEnhanceを掛けないと画像の乱れがなかなかに凄いです。
A captivating young girl, bathed in soft, ethereal light, stands with a sense of grace and wonder. Her eyes sparkle with curiosity, reflecting the world around her. She is adorned in a simple yet elegant dress, the fabric flowing gently in the breeze. The scene is set in a whimsical forest, with towering trees and vibrant flora, creating a magical atmosphere that encapsulates the spirit of youth and imagination.
Anime Model

Polyart Model(Express)

Polyart Model(Premium)

基本的にどのモデルを使用したとしても大きく差が出ることはなさそうです。一つ明らかになったことは、VIVAGOは画像生成も強い……ということですね。
使用した感想
動画や画像の精度は非常に高く、今後も期待が持てるサービスです。特に優秀だと感じた要素は以下。
- Extendが際限なく出来て凄い
- 画像生成の品質が単純に高い
- Keyframeがまあまあ滑らか
ご参考までに、大部分をVIVAGOの画像生成とKeyframeで賄った動画が以下です。
ここまでポジティブな感想を述べてみましたが不満も多少はあります。質が高いゆえか生成速度はやや遅く、これを書いている現在はPlusプランに加入していますがそれでも若干遅く感じます。もしかしたらProプランだと爆速……なのかもしれませんが、金額を考えると流石にちょっと躊躇しちゃいますね。
とはいえ、無料でも利用可能な動画/画像生成サービスとしては全体的に高水準の性能であり、最近の生成AIサービスの中でも上位に位置するかと思われます。










